
Introduction
Real-time speech applications rarely operate in ideal acoustic environments. In enterprise scenarios—sales calls, support sessions, and hybrid meetings—audio often includes echo from remote participants, background noise from laptops, and overlapping speech. These acoustic artifacts degrade speech recognition accuracy and increase downstream processing complexity.
In previous posts, AMAX engineers explored how NVIDIA® Riva enables real-time, on-prem speech recognition for enterprise workloads. As that work progressed into real customer-like scenarios, one challenge became increasingly clear: audio quality matters as much as model quality.
This is where NVIDIA Maxine™ SDK plays a critical role.
Maxine provides GPU-accelerated audio enhancement capabilities such as Acoustic Echo Cancellation (AEC) and Background Noise Removal (BNR). In this post, AMAX engineers share how we integrated Maxine SDK into our existing Riva-based voice AI pipeline, the architectural decisions involved, and what we learned while deploying it in real-world environments.
Why Audio Enhancement Matters in Enterprise Voice AI
Most speech recognition models assume reasonably clean input audio. In practice, enterprise voice workflows introduce challenges such as:
- Far-end audio leaking into the microphone path
- Laptop speakers causing echo loops
- HVAC, keyboard, and ambient noise
- Variability across devices and operating systems
During early testing, AMAX engineers observed that these issues could cause:
- Increased transcription fragmentation
- Delayed stabilization of interim results
- Reduced accuracy on domain-specific terminology
Rather than attempting to compensate for these issues purely at the ASR layer, we explored audio pre-processing using NVIDIA Maxine SDK.
Overview of NVIDIA Maxine SDK
NVIDIA Maxine SDK is a collection of GPU-accelerated audio and video enhancement libraries designed for real-time communication applications. For voice AI workloads, two capabilities are particularly relevant:
- Acoustic Echo Cancellation (AEC) – removes far-end audio from near-end microphone signals
- Background Noise Removal (BNR) – suppresses ambient noise while preserving speech quality
Maxine SDK is delivered as a C++ SDK and runs on both Windows and Linux systems. Unlike cloud-based audio processing services, Maxine operates entirely on-prem and can be integrated directly into existing real-time pipelines.
Architecture: Integrating Maxine into a Riva-Based Voice AI Pipeline
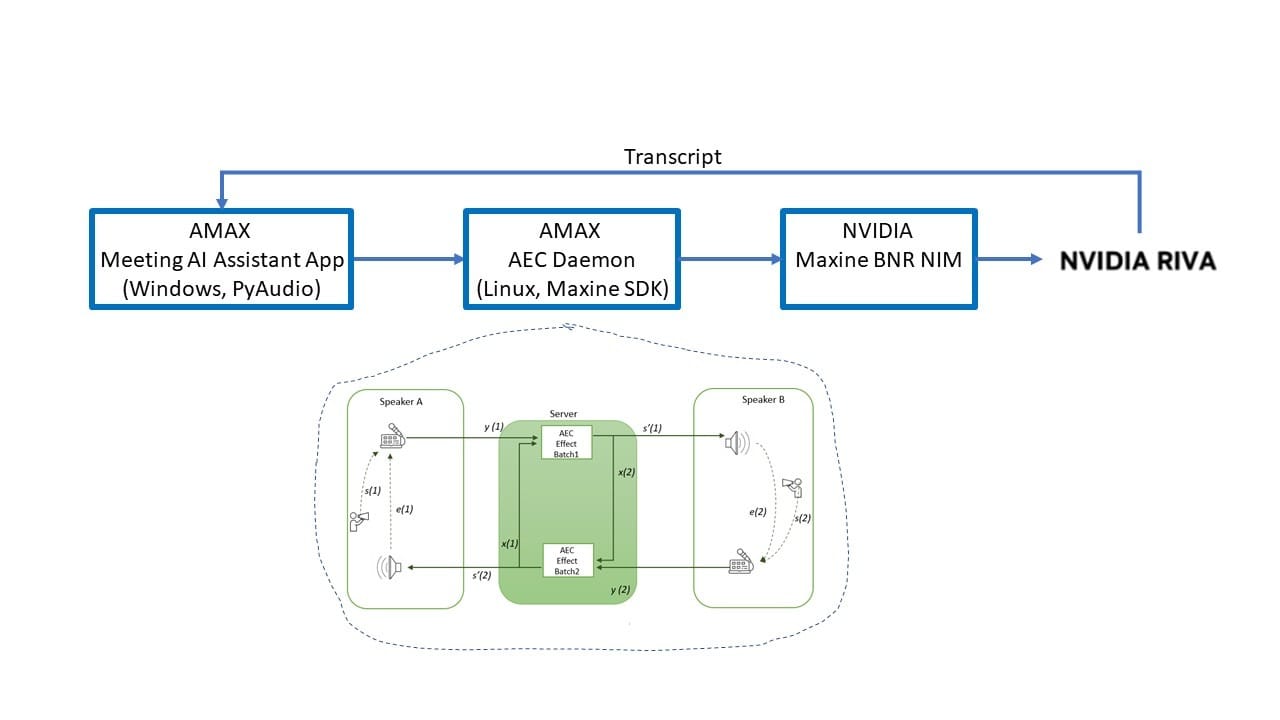
AMAX engineers implemented Maxine as part of a proxy-style architecture that sits between audio capture clients and the Riva ASR service.
High-level flow:
- Client captures:
- Near-end microphone audio
- Far-end loopback/system audio
- Audio streams are paired and time-aligned
- Maxine AEC removes echo artifacts
- Optional Maxine BNR reduces background noise
- Cleaned audio is forwarded to Riva ASR
- Transcripts are returned to the client
This design allowed us to enhance audio quality without modifying Riva itself, keeping responsibilities cleanly separated.
Key Implementation Considerations
Time Alignment Is Critical for AEC
One of the most important lessons learned was that AEC depends on precise alignment between microphone and loopback audio. Even small timing drift reduces cancellation effectiveness.
To address this, we implemented a Metronome-based pairing mechanism in the Python client. Rather than streaming audio directly from device callbacks, both streams are buffered and released at fixed intervals, ensuring each AEC frame contains synchronized near-end and far-end audio.
This design significantly improved echo cancellation quality across different devices and operating systems.
Metronome-Based Audio Pairing (Python Client)
To ensure NVIDIA Maxine AEC receives precisely aligned near-end (microphone) and far-end (loopback) audio frames, AMAX engineers implemented a Metronome-based pairing mechanism in the Python client.
Instead of streaming audio directly from device callbacks—which may fire at different times—the client buffers both streams and releases paired frames on a fixed clock. This guarantees that each AEC frame contains synchronized audio with a consistent time base.
Key idea
- Audio callbacks → ring buffers
- Metronome thread → fixed cadence (e.g., 10–20 ms)
- Each tick → exactly one paired frame
- Missing samples → padded with silence
Simplified implementation
RATE = 16000 # Riva/AEC expects 16 kHz
FRAME = 160 # 10 ms @ 16 kHz
BYTES = FRAME * 2 # PCM16 mono bytes per frame
class SyncedAudioBuffer:
"""Thread-safe dual buffer for mic + loopback audio."""
def __init__(self, rate=RATE):
self.rate = rate
self.mic = bytearray()
self.loop = bytearray()
self.mic_lock = threading.Lock()
self.loop_lock = threading.Lock()
def add_mic(self, data: bytes):
with self.mic_lock:
self.mic.extend(data)
def add_loop(self, data: bytes):
with self.loop_lock:
self.loop.extend(data)
def take_pair(self, n_bytes: int):
"""Only succeed when BOTH buffers have at least n_bytes."""
with self.mic_lock:
if len(self.mic) < n_bytes:
return None, None, False
with self.loop_lock:
if len(self.loop) < n_bytes:
return None, None, False
with self.mic_lock:
mic_chunk = bytes(self.mic[:n_bytes])
del self.mic[:n_bytes]
with self.loop_lock:
loop_chunk = bytes(self.loop[:n_bytes])
del self.loop[:n_bytes]
return mic_chunk, loop_chunk, True
def resync_if_needed(self, max_diff_ms: float = 100.0):
"""Trim the longer buffer to match the shorter one (avoid drift buildup)."""
with self.mic_lock:
mic_ms = (len(self.mic) / (self.rate * 2)) * 1000
with self.loop_lock:
loop_ms = (len(self.loop) / (self.rate * 2)) * 1000
if abs(mic_ms - loop_ms) <= max_diff_ms:
return False
target = None
with self.mic_lock, self.loop_lock:
target = min(len(self.mic), len(self.loop))
self.mic = self.mic[-target:]
self.loop = self.loop[-target:]
return True
def metronome_loop(audio_buf: SyncedAudioBuffer, out_q: queue.Queue, stop: threading.Event):
"""Emit exactly one synchronized (mic, loopback) pair every 10 ms."""
seq = 0
base_ms = int(time.time() * 1000)
period_s = FRAME / RATE # 10 ms
next_t = time.perf_counter()
last_sync_check = time.time()
while not stop.is_set():
next_t += period_s
ts_ms = base_ms + seq * 10
# Periodically resync buffers to prevent drift
now_wall = time.time()
if now_wall - last_sync_check > 1.0:
audio_buf.resync_if_needed(max_diff_ms=100.0)
last_sync_check = now_wall
mic_chunk, loop_chunk, ok = audio_buf.take_pair(BYTES)
if ok:
out_q.put_nowait({
"mic_chunk": mic_chunk,
"loopback_chunk": loop_chunk,
"seq": seq,
"sample_rate": RATE,
"num_samples": FRAME,
"timestamp_ms": ts_ms,
})
seq += 1
# Keep a stable cadence
now = time.perf_counter()
if next_t > now:
time.sleep(next_t - now) Why this matters for Maxine AEC
Acoustic Echo Cancellation assumes that near-end and far-end audio frames represent the same moment in time. Even small timing drift between streams can significantly reduce cancellation effectiveness.
By enforcing a single, stable metronome clock, this approach:
- keeps microphone and loopback audio aligned,
- prevents drift caused by OS scheduling or driver behavior,
- improves echo suppression consistency across devices,
- and produces cleaner input for downstream Riva ASR.
This mechanism proved essential when running Maxine AEC in real-world enterprise environments, particularly on Windows systems where audio devices operate asynchronously.
Running Maxine AEC in a Real-Time Loop
A simplified Maxine AEC initialization flow:
NvAFX_Handle handle;
NvAFX_CreateEffect(NVAFX_EFFECT_AEC, &handle);
NvAFX_SetString(handle, NVAFX_PARAM_MODEL_PATH, model_path.c_str());
NvAFX_SetU32(handle, NVAFX_PARAM_INPUT_SAMPLE_RATE, 16000);
NvAFX_Load(handle);Each audio frame is converted to float format, processed by Maxine, then converted back to PCM before streaming to Riva.
Observed Impact on Transcription Quality
While Maxine introduces a small fixed processing overhead, AMAX engineers observed several practical benefits:
- Reduced echo-induced misrecognitions
- More stable interim transcripts
- Fewer false utterance boundaries
- Improved readability for downstream processing such as translation and RAG
In hybrid meeting scenarios, the combination of AEC + BNR + Riva produced noticeably cleaner transcripts compared to ASR alone.
Why This Matters for Enterprise Voice AI
By integrating Maxine SDK into the voice AI pipeline, AMAX demonstrated how audio enhancement and speech recognition work best as complementary layers rather than isolated components.
For enterprises deploying on-prem voice AI solutions, this architecture provides:
- Better transcription quality in real-world environments
- Fully private, GPU-accelerated processing
- A modular design that can evolve with new models and features
AMAX's Role
AMAX engineers design and validate complete AI pipelines that combine GPU infrastructure, NVIDIA AI Enterprise software, and real application workflows. Our work with Maxine SDK builds on our existing Riva-based voice AI efforts, creating a reference architecture that addresses both audio quality and speech intelligence.
By deploying and testing these solutions internally, AMAX helps customers move from proof-of-concept voice AI to production-ready, enterprise-grade systems.