
The NVIDIA Blackwell Platform
The rise of generative AI is delivering real benefits for businesses in every sector. The goal now is to develop AI platforms that lower costs to make AI adoption quicker and more widespread, enabling all businesses to benefit from the advancements of AI.
The new NVIDIA Blackwell architecture marks a significant leap in generative AI and accelerated computing. It features the second generation Transformer Engine and an enhanced NVIDIA® NVLink® interconnect, significantly boosting data center performance far beyond the previous generation. With the latest in NVIDIA Confidential Computing, it ensures high security for large language model (LLM) inference at scale, maintaining performance. The introduction of a new Decompression Engine and integration with Spark RAPIDS™ libraries push database performance to new heights, opening up a potential $100 billion market in accelerated computing. Blackwell's innovations redefine the future of generative AI, offering unmatched performance, efficiency, and scalability.
NVIDIA Blackwell Configurations
Available in three models, Blackwell GPUs cater to a range of computing needs:
- NVIDIA DGX™GB200 NVL72: A Blackwell platform that connects 36 Grace CPUs and 72 Blackwell GPUs in a rack-scale design. The GB200 NVL72 is a liquid-cooled, rack-scale solution.
- NVIDIA DGX™ B200: A Blackwell platform that combines 8x NVIDIA Blackwell GPUs with 1,440GB of GPU to deliver 72 petaFLOPS training and 144 petaFLOPS inference.
- NVIDIA HGX™ B200: A Blackwell x86 platform based on an eight-Blackwell GPU baseboard, delivering 144 AI petaFLOPs
- NVIDIA HGX™ B100: Blackwell x86 platform based on an eight-Blackwell GPU baseboard, delivering 112 AI petaFLOPs. HGX B100 is a drop-in compatible upgrade for NVIDIA Hopper™ systems in existing data center infrastructure.
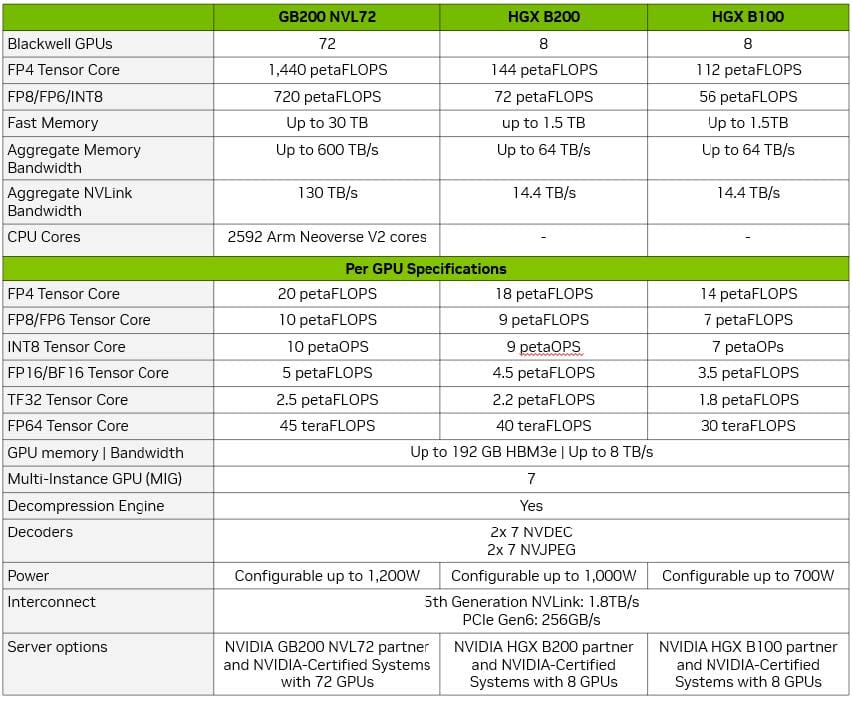
NVIDIA Blackwell Specifications
NVIDIA GB200 NVL72, HGX B200, HGX B100
NVIDIA DGX B200
| Specification | Details |
|---|---|
| GPUs | 8x NVIDIA Blackwell, 1,440GB GPU Memory |
| Performance | 72 petaFLOPS (training), 144 petaFLOPS (inference) |
| System Power | ~14.3kW max |
| CPU | 2 Intel® Xeon® Platinum 8570 (112 Cores, up to 4 GHz) |
| System Memory | Up to 4TB |
| Networking | Up to 400Gb/s Ethernet/InfiniBand, 10Gb/s NIC |
| Storage | OS: 2x 1.9TB NVMe M.2, Internal: 8x 3.84TB NVMe U.2 |
| Software | NVIDIA AI Enterprise, DGX OS / Ubuntu |
| Physical | 10 RU, 17.5in x 19.0in x 35.3in |
| Operating Temp. | 5–30°C (41–86°F) |
Power and Infrastructure Considerations
The NVIDIA DGX B200 is a powerhouse in terms of performance and, correspondingly, power consumption. Operating the DGX B200 requires approximately 14.3 kW of power. In a typical data center configuration, this translates to around 60 kW of rack power when factoring in additional system components and potential peak usage scenarios. This highlights the need for a data center infrastructure equipped to handle such high power demands effectively.
Alternative configurations within the same family can consume between 700 to 1200 watts per unit. In densely populated racks, this could lead to an overall energy demand of up to 120 kW per rack. Managing this energy consumption requires not only a capable power supply but also advanced cooling solutions to dissipate the generated heat efficiently.
Data centers planning to deploy these high-performance units must ensure that their infrastructure is not only capable of delivering the required power but also adept at managing the substantial heat output. This involves planning for:
- Enhanced Power Infrastructure: Facilities must be equipped with power distribution units and backup systems designed to handle loads significantly above the average energy consumption, ensuring uninterrupted operations even under peak load conditions.
- Advanced Cooling Systems: Effective thermal management is crucial. While traditional air-cooled systems are common, the intense heat output by high-performance computing systems like the DGX B200 often necessitates more sophisticated solutions, such as liquid cooling systems.
AMAX specializes in providing cutting-edge liquid cooling technologies that are crucial for maintaining optimal temperatures in these environments. By integrating these advanced cooling solutions, data centers can not only achieve more efficient heat dissipation but also enhance system performance and reliability.
To accommodate a system as powerful as the NVIDIA DGX B200, data centers must consult with thermal management experts and invest in infrastructure that supports high electrical and thermal loads. Leveraging AMAX’s expertise in advanced liquid cooling technology ensures that these high-density configurations operate within safe thermal thresholds, preventing overheating and maximizing the longevity and performance of the hardware.
NVIDIA GB200 NVL72 Overview

The NVIDIA GB200 NVL72 forms a powerful network by connecting 36 Grace CPUs and 72 Blackwell GPUs in a rack-scale setup, dramatically enhancing capabilities in generative AI, data analytics, and high-performance computing tasks. This solution leverages a liquid-cooling system and is designed to function as a cohesive 72-GPU NVLink domain, mimicking a singular, enormous GPU. This architecture achieves a 30-fold increase in speed for real-time inference on models with trillions of parameters.
Central to the NVIDIA GB200 NVL72 is the GB200 Grace Blackwell Superchip, which links two high-performance Blackwell GPUs and one NVIDIA Grace CPU. This connection utilizes the 900 GB/s NVLink-C2C interconnect, facilitating rapid communication between the GPUs.
NVIDIA GB200 NVL72 AI Capabilities
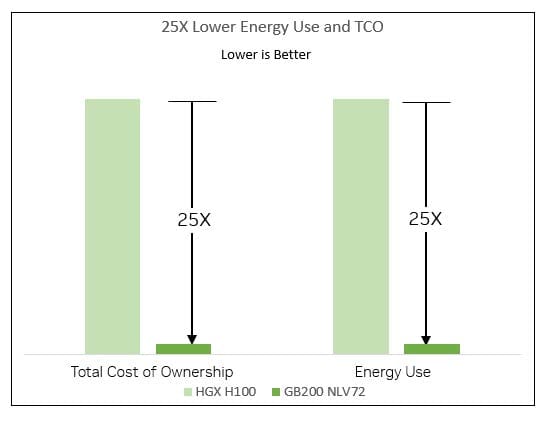
This model introduces a new era in real-time inference by incorporating a second-generation Transformer Engine and enhanced Tensor Cores that accelerate language model inferences. As a result, the GB200 NVL72 can deliver computations 30 times faster than its predecessors, such as the HGX H100, while significantly reducing total cost of ownership and energy consumption by 25 times for handling complex models like GPT-MoE-1.8T1. The use of NVLink and an efficient liquid cooling system addresses communication challenges within this expansive 72-GPU array, setting a new standard for performance in high-demand AI tasks and underscoring NVIDIA's dedication to advancing AI technology.
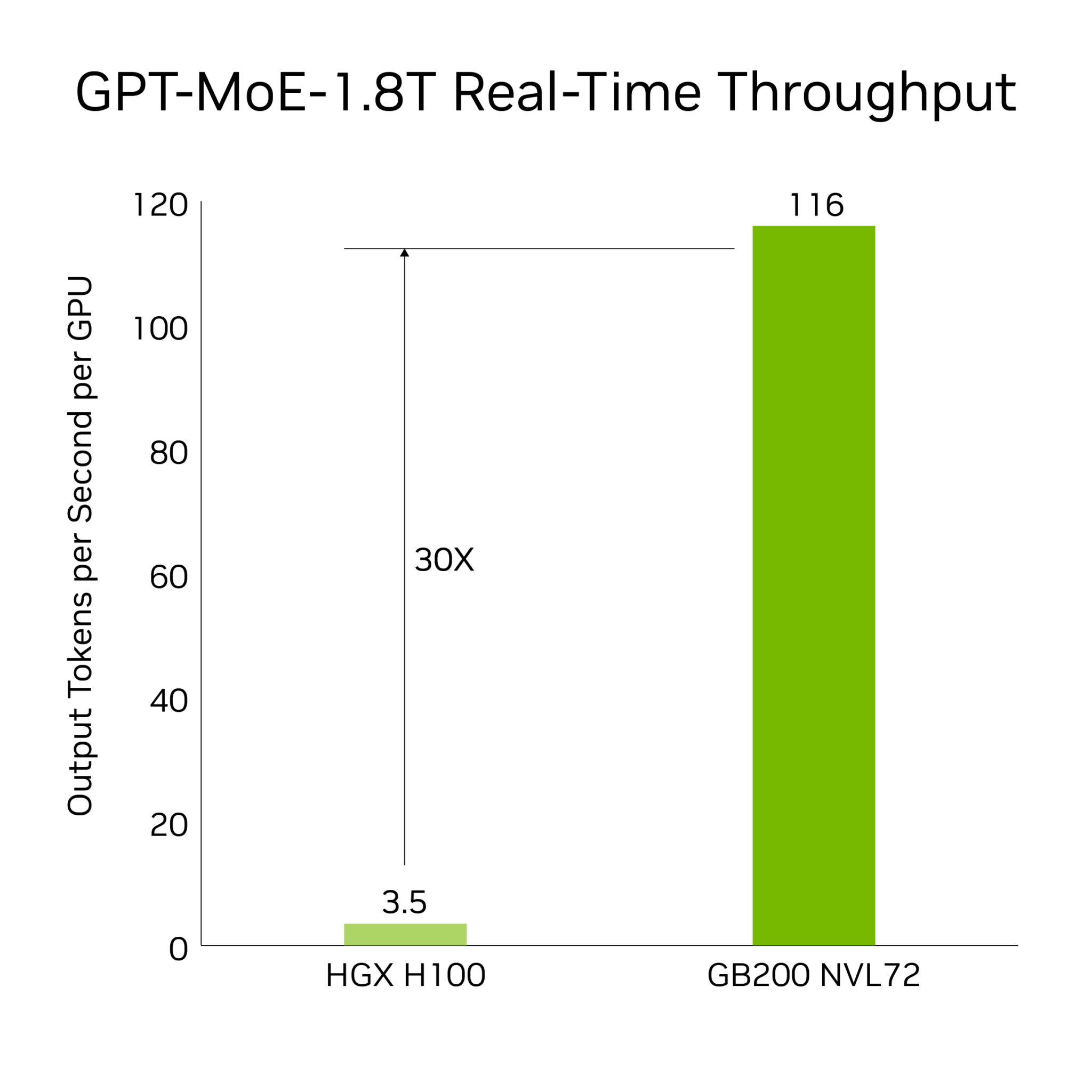
GB200 NVL72 AI Training Performance
The GB200 NVL72 leverages an upgraded, second-generation Transformer Engine with FP8 precision, achieving training speeds up to four times faster for complex language models such as GPT-MoE-1.8T, compared to the previous Hopper generation. This acceleration results in a ninefold decrease in the required rack space and a reduction of both total cost of ownership and energy consumption by 3.5 times. This advancement is supported by the fifth-generation NVLink, offering a 1.8TB/s GPU-to-GPU connection within a more extensive 72-GPU NVLink framework, along with InfiniBand networking and NVIDIA Magnum IO™ software. These technologies work in concert to promote efficient scaling for large enterprises and GPU-intensive computing environments.
GB200 NVL72 Network Infrastructure for AI
The GB200 NVL72 operates as a singularly powerful computing entity and necessitates strong networking capabilities for peak application performance. In conjunction with NVIDIA Quantum-X800 InfiniBand, Spectrum-X800 Ethernet, and BlueField-3 DPUs, the GB200 sets new standards in performance, efficiency, and security for large-scale AI data centers. The Quantum-X800 InfiniBand serves as the cornerstone of the AI computing network, supporting expansion up to and beyond 10,000 GPUs within a highly efficient two-level fat tree architecture—representing a fivefold increase over the prior Quantum-2 generation. To facilitate data center-wide scaling, the NVIDIA Spectrum-X800 and BlueField-3 DPU platforms enable rapid GPU data access, secure cloud environments for multiple tenants, and streamlined data center management.
NVIDIA DGX B200

The NVIDIA DGX™ B200 is designed to address the escalating demands for compute capacity that modern AI workloads require, the DGX B200 delivers a combination of high-performance computing, storage, and networking capabilities. This unified AI platform is engineered to handle the complexities of training, fine-tuning, and inference phases of AI development, marking a significant milestone in generative AI.
AI Performance
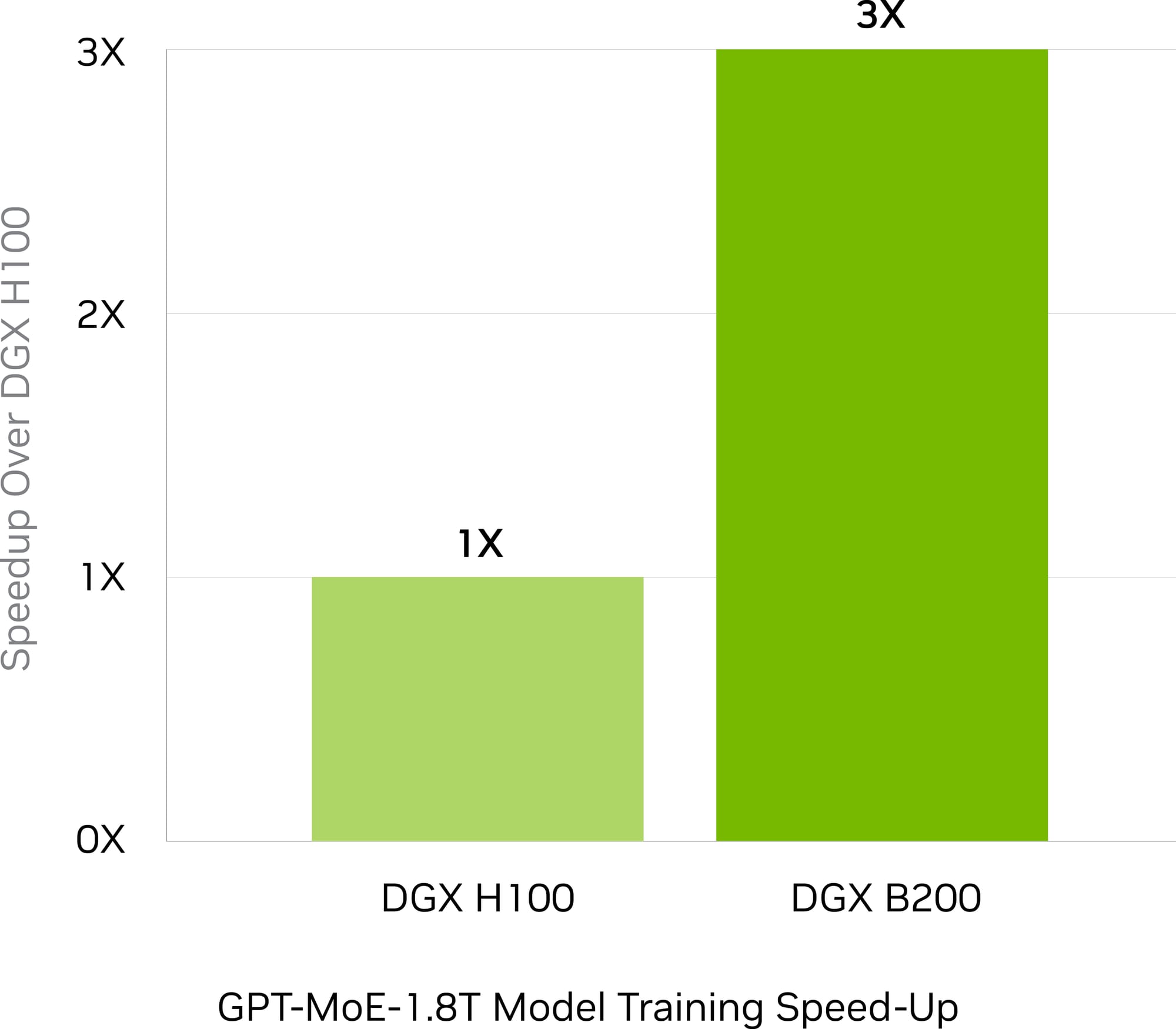
The DGX B200 represents NVIDIA's commitment to developing the world's most powerful supercomputers for AI. Powered by the NVIDIA Blackwell architecture, it delivers three times the training performance and fifteen times the inference performance compared to its predecessors.
This powerhouse of AI computing forms the core of NVIDIA's DGX POD™ reference architectures, offering scalable, high-speed solutions for turnkey AI infrastructures.
NVIDIA HGX Blackwell B200 Overview

The NVIDIA Blackwell HGX™ platforms mark the beginning of a new chapter in data center evolution, focusing on accelerating computing and generative AI. These platforms combine NVIDIA Blackwell GPUs with advanced interconnect technologies, significantly enhancing AI performance on a large scale. As a leading accelerated computing platform optimized for x86 architecture, Blackwell HGX offers up to 15 times faster real-time inference performance, all while being 12 times more cost-effective and energy-efficient. This makes it ideally suited for the most rigorous AI, data analytics, and high-performance computing (HPC) tasks.
Advancements in Real-Time Language Model Processing
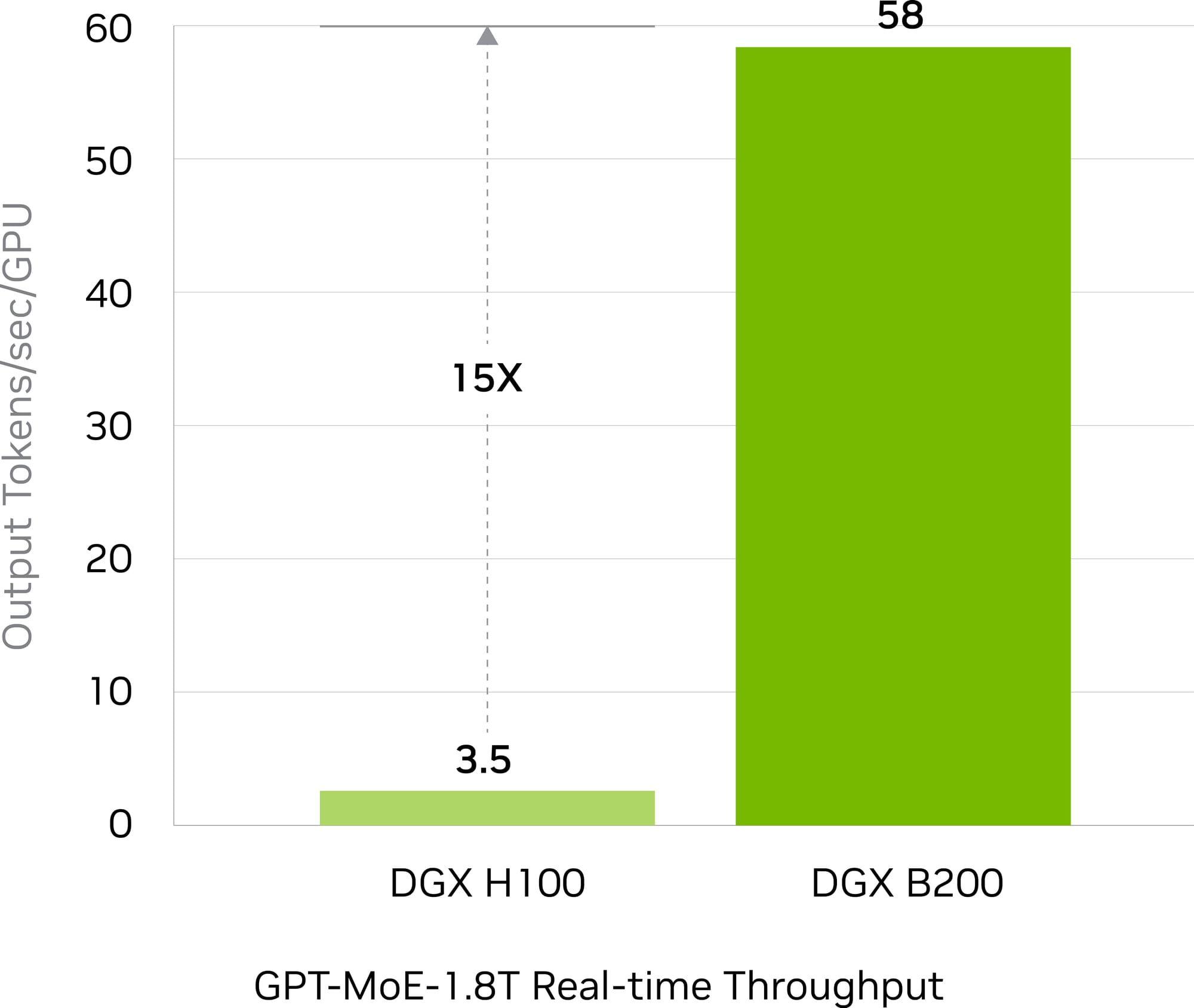
Within the HGX lineup, the Blackwell GPUs bring to the table unparalleled capabilities thanks to the second-generation Transformer Engine, propelling the acceleration of inference workloads to new heights. This technology enables real-time processing capabilities for complex, multi-trillion-parameter language models. The HGX B200, for instance, delivers a 15-fold increase in speed, 12-fold reduction in cost, and 12-fold decrease in energy consumption compared to previous generation models for large-scale projects like the GPT-MoE-1.8T. These improvements are facilitated by the latest generation of Tensor Cores, introducing new levels of precision, including FP4.
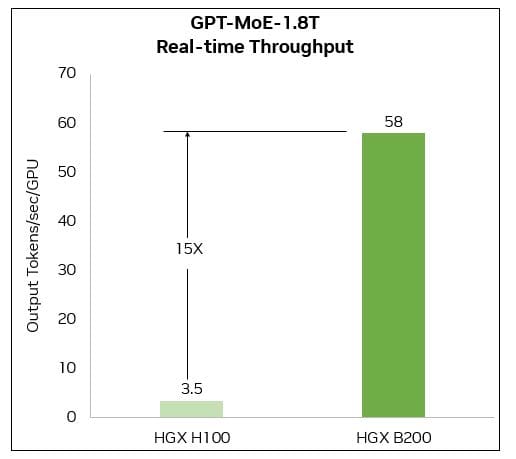
HGX B200 AI Training Performance
Blackwell GPUs feature an advanced, second-generation Transformer Engine with FP8 precision, offering a significant 3X speed increase in training large language models such as GPT-MoE-1.8T over the previous Hopper generation. This enhancement is supported by the latest fifth-generation NVLink, delivering 1.8TB/s GPU-to-GPU connectivity, alongside InfiniBand networking and Magnum IO software. This combination of technologies ensures scalable and efficient performance for enterprise-level and large GPU computing clusters.
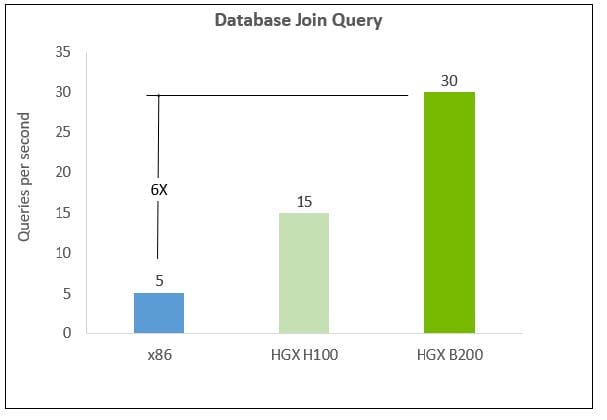
HGX B200 Data Analytics
In the realm of data analytics, databases and Apache Spark are essential for managing, processing, and analyzing vast datasets. The introduction of Blackwell's specialized Decompression Engine significantly enhances the efficiency of database query operations, setting new benchmarks in performance for data analytics and data science fields. By accommodating modern compression standards like LZ4, Snappy, and Deflate, HGX B200 GPUs achieve query processing speeds that are six times faster than traditional CPUs and twice as fast as the H100, illustrating a notable advancement in analytical capabilities.
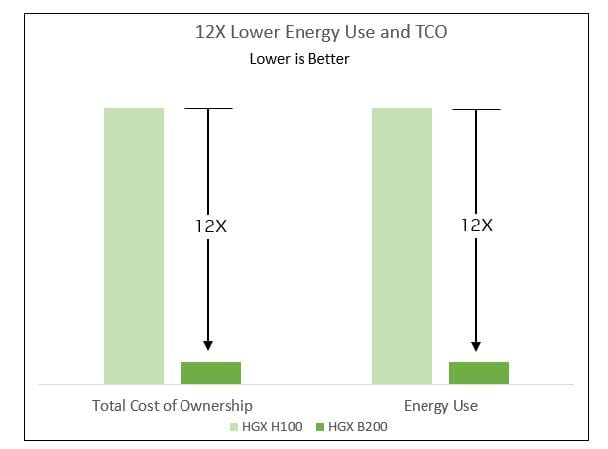
HGX B200 TCO Savings
Implementing eco-friendly computing strategies enables data centers to reduce their environmental impact and energy usage, while also enhancing their financial performance. Achieving sustainable computing is possible through the efficiency improvements provided by accelerated computing technologies like HGX. Specifically, for LLM inference tasks, the HGX B200 model boosts energy efficiency by 12 times and reduces expenses by an equal measure when compared to its predecessor, the Hopper generation.
HGX B100 Overview

The NVIDIA HGX™ B100 powers accelerated computing and generative AI by merging NVIDIA Blackwell GPUs with the high-speed NVIDIA NVLink interconnect, enhancing AI capabilities significantly. With eight GPU setups, it offers unmatched acceleration for generative AI tasks, featuring an impressive 1.4 terabytes (TB) of GPU memory and 60 terabytes per second (TB/s) of memory bandwidth, facilitating real-time inference for models with trillions of parameters. This powerful combination establishes the HGX B100 as a leading accelerated computing platform on the x86 architecture, optimized for rapid deployment with easy integration into existing HGX H100 setups.
The HGX B100 is equipped with state-of-the-art networking capabilities, achieving speeds of up to 400 gigabits per second (Gb/s). This ensures top-tier AI performance supported by NVIDIA Quantum-2 InfiniBand and Spectrum™-X Ethernet platforms. Paired with NVIDIA® BlueField®-3 data processing units (DPUs), the HGX B100 enhances cloud network functionality, storage modularity, uncompromised security, and flexible GPU computing, making it ideal for large-scale AI cloud environments.
AMAX Solutions designed for NVIDIA Blackwell
The AMAX IntelliRack series features a wide selection of liquid-cooled rack systems designed to meet diverse infrastructure needs. Compatible with the latest NVIDIA GPU models, including H100, H200, GH200, B200, B100, and GB200, our systems are equipped to handle your sophisticated computing requirements. These racks are especially relevant for AI data centers seeking advanced cooling solutions.

Engineered for the AI era, our IntelliRack solutions efficiently manage cooling for systems with power consumption needs up to 100kw, despite the GB200 GPUs drawing 1200W each. This capability makes them ideal for environments that demand high power and cooling efficiency. Whether your organization already implements a facility water system or is considering the adoption of liquid cooling technologies, our racks provide a versatile solution. Built according to the latest OCP ORv3 design standards, they offer significant power savings and operational efficiency for a variety of needs.