

Companies are increasingly adopting vector databases due to their ability to handle massive volumes of unstructured data such as text, images, and audio files. These databases excel in advanced search, particularly in similarity searches, critical for applications such as recommendation systems and natural language processing (NLP). Their scalable nature ensures they keep pace with growing data and computational needs, making them suitable for dynamic business environments.
Vector databases compatibility with AI and machine learning models further advances data analysis and decision-making. The capability for real-time data processing in scenarios like fraud detection adds to their appeal, offering businesses the opportunity to gain insights quickly and stay competitive in their respective markets.
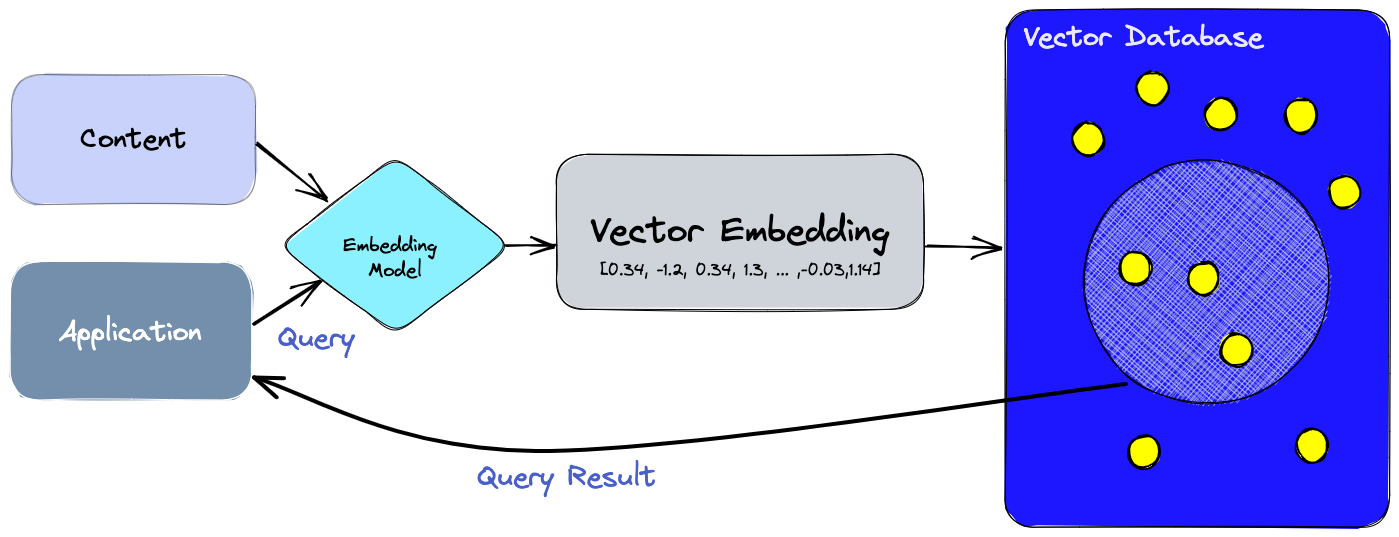
What are Vector Databases?
Vector databases are a specialized type of database designed to efficiently store, manage, and query vector data. Vector data, in this context, refers to data represented in multi-dimensional vector space, typically derived from embedding algorithms used in machine learning.
These embeddings transform complex and unstructured data like text, images, and audio into numerical vector formats that are more easily processed by machine learning models.
Why Companies are Adopting Vector Databases
For many businesses these databases are a most useful when it comes to efficiently managing large amounts of unstructured data. Vector databases also stand out for their enhanced search capabilities. They excel in similarity searches, a critical feature for applications like recommendation engines, image retrieval systems, and NLP tools. The ability to accurately identify similar items or content can quickly deliver relevant and personalized user experiences.
Scalability is another important factor of vector databases, making them ideal for dynamic business environments. Designed to keep pace with a company's growth, these databases scale in response to increasing data volumes and computational demands. This scalability ensures that as businesses evolve, their data infrastructure does too, continuously providing efficient and effective service.
The capability of vector databases to store and process data in a format readily usable for machine learning models opens up avenues for more sophisticated AI-driven applications. This integration plays a crucial role in leveraging AI technologies for innovative solutions and competitive advantages. In scenarios such as fraud detection or real-time personalization strategies - the ability of these databases to process information on the fly is invaluable. It enables businesses to make quick, data-driven decisions in response to real-time events.
Vector databases represent a strategic asset for businesses looking to capitalize on their data. Their blend of efficient data management, advanced search capabilities, scalability, AI integration, and real-time processing makes them a critical tool in the modern business environment. This combination not only supports current operational needs but also paves the way for future innovations and growth.
Vector Database vs Retrieval Augmented Generation (RAG)
Vector databases and RAG (Retriever-Augmented Generation), while different in function, complement each other in terms of AI and machine learning. RAG, a sophisticated NLP model, consists of two parts: a retriever that sources relevant information from a large database, and a generator that uses this information to create coherent, context-aware responses. This makes RAG ideal for applications needing deep language understanding, such as chatbots or content creation tools.
Vector databases, in contrast, are specialized databases designed to efficiently handle and retrieve vector data - numerical representations of complex entities like text and images. Their strength lies in managing large volumes of unstructured data and performing fast similarity searches, essential for AI tasks that require quick and accurate data retrieval.
Together, these technologies play complementary roles: vector databases enhance RAG's performance by providing a an efficient data retrieval mechanism. This combination allows RAG models to access the most relevant data quickly, thereby improving the accuracy and contextuality of their outputs.
Open-Source vs Proprietary Vector Databases
When deciding between open-source and proprietary vector databases, companies consider various factors. Open-source databases offer cost-effectiveness, as they are usually free, and provide flexibility for customization to meet specific needs. They also benefit from strong community support, which contributes to regular updates and a wealth of shared knowledge. Additionally, open-source solutions offer transparency in their code, enhancing security and trust. Another advantage is avoiding vendor lock-in, providing companies with long-term flexibility and independence.
On the other hand, proprietary vector databases come with comprehensive support and services, which can be crucial for businesses lacking in-house expertise. They often include advanced features and optimizations tailored for enterprise-level requirements. These databases might offer specific compliance guarantees for regulatory standards, crucial in certain industries, Proprietary solutions are generally more user-friendly, with intuitive interfaces and easier deployment, suitable for companies seeking ready-to-use solutions. They also tend to offer more stability in terms of product roadmaps and long-term planning. Ultimately, the choice depends on a company's specific needs, resources, and strategic objectives, balancing factors like cost, customization, support, and ease of use.
Top 5 Open-source Vector Databases
Vector databases are uniquely equipped to handle high-dimensional vector data, making them ideal for a range of advanced applications, from natural language processing to image retrieval. Here's a look at the top 5 open-source vector databases, each with its distinct features and capabilities, offering innovative solutions for managing complex data effectively.
Chroma
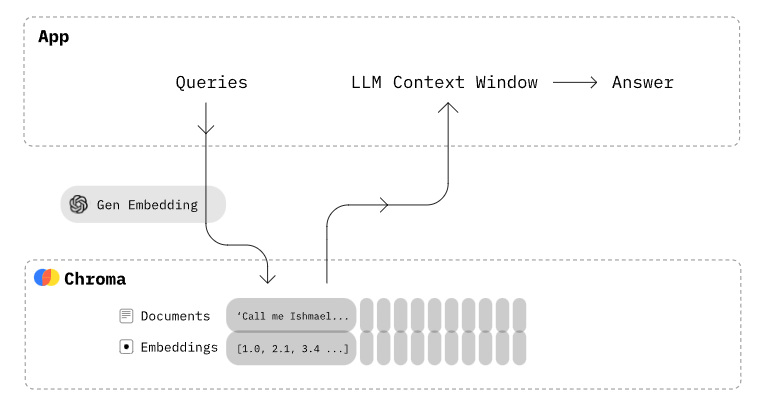
An open-source embedding database aimed at simplifying the development of Large Language Model (LLM) applications. It's particularly effective for managing text documents and transforming text into embeddings.
Key Features:
- Rich features for queries, filtering, and density estimates.
- Support for LangChain in Python and JavaScript.
- Scales efficiently from Python notebooks to production clusters.
Weaviate
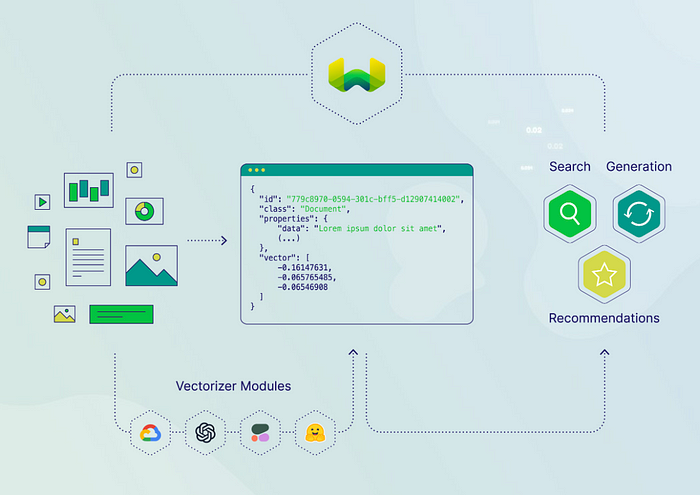
An open-source vector database that allows storage of data objects and vector embeddings from various ML models, scaling to manage billions of objects.
Key Features:
- Quick search capabilities for large datasets.
- Flexible data vectorization during import or use of own vectors.
- Integrations with platforms like OpenAI, Cohere, and HuggingFace.
- Focus on scalability, replication, and security for production readiness.
Milvus
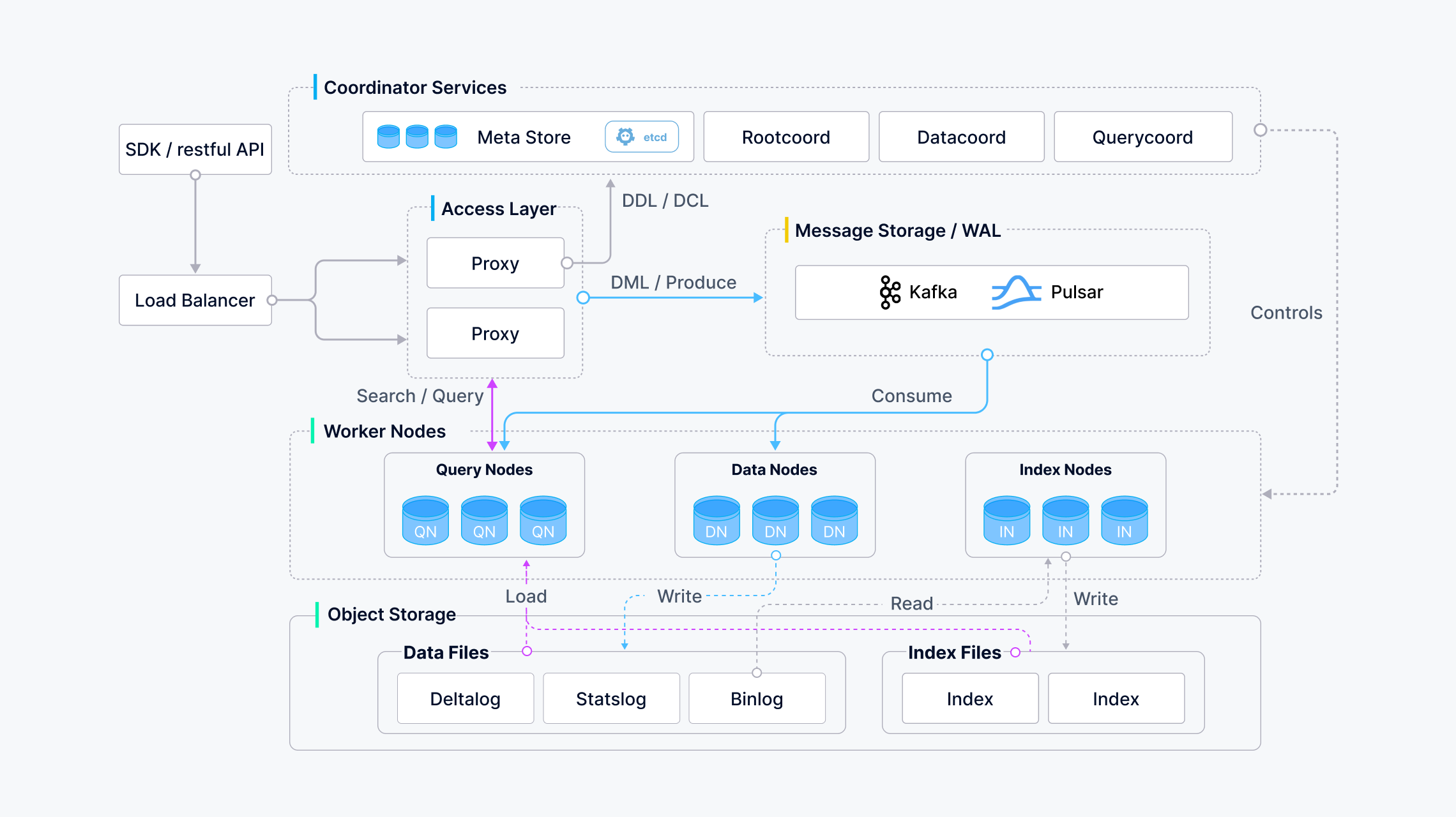
A powerful open-source vector database designed for AI applications and similarity searches, offering a consistent user experience across various deployment environments.
Key Features:
- Cloud-native with separated storage and computation for enhanced elasticity.
- Millisecond search on trillion vector datasets.
- Hybrid search solution combining scalar filtering with vector similarity.
- High scalability and flexibility with component-level scaling on demand.
Qdrant
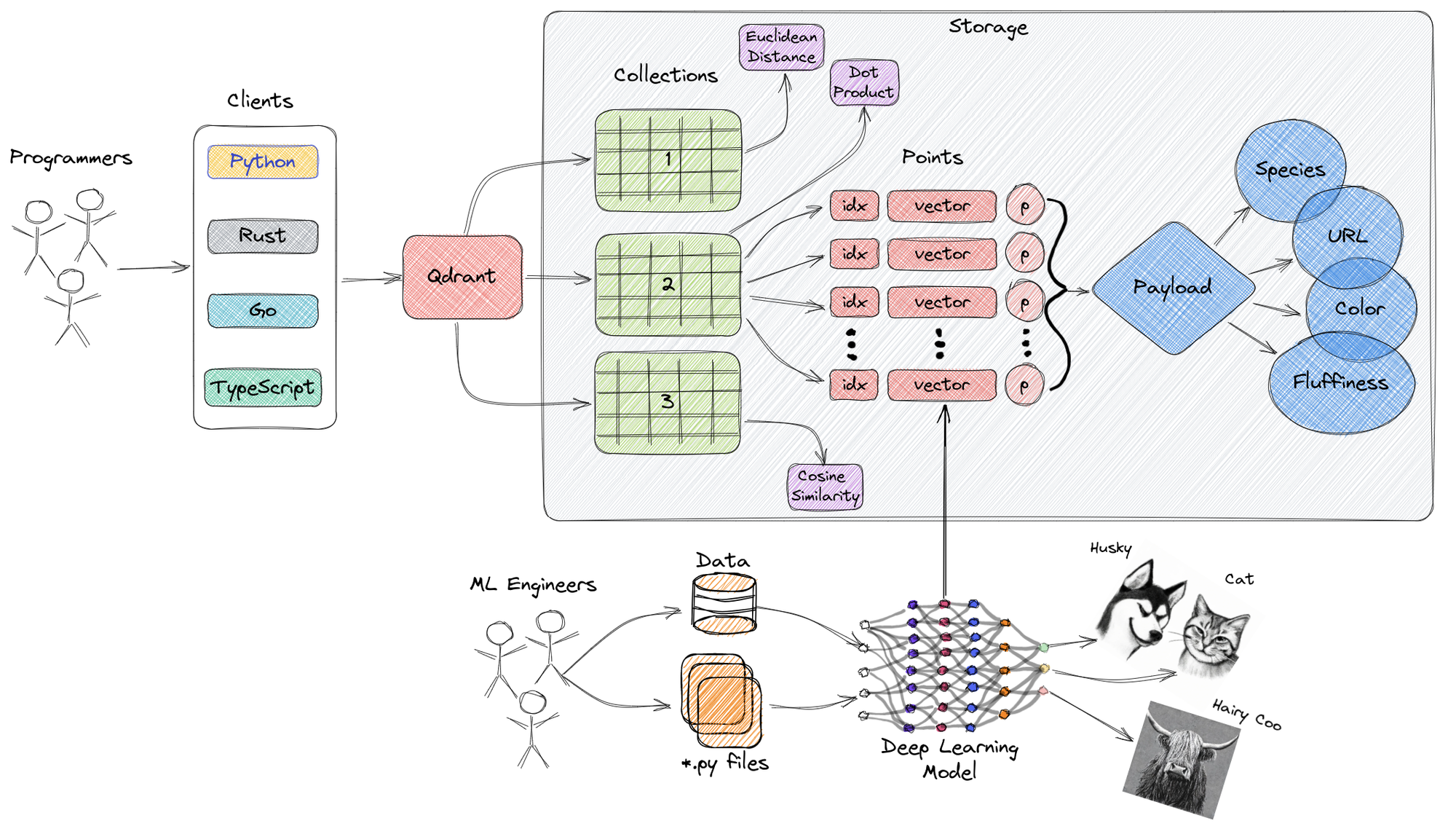
An open-source vector similarity search engine and database, providing a production-ready service with a user-friendly API.
Key Features:
- Payload-based storage and filtering.
- Support for various data types and query criteria.
- Efficient query execution with cached payload information.
- Robustness with write-ahead logging during power outages.
Faiss
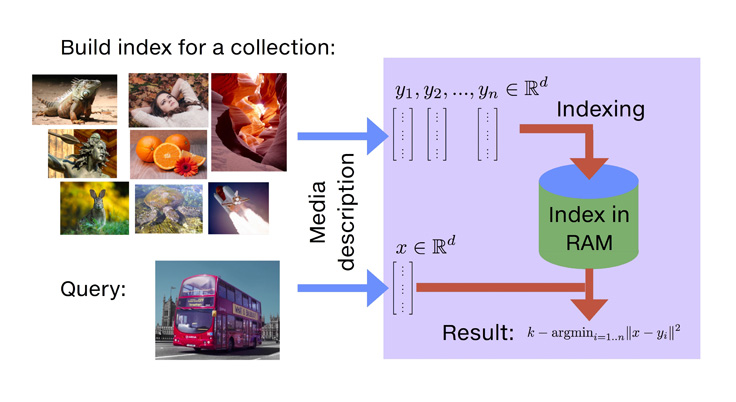
Developed by Facebook AI Research, Faiss is an open-source library for fast, dense vector similarity searches and clustering.
Key Features:
- Efficient search across massive vector sets, even exceeding RAM capacity.
- Various search methods using L2 distances, dot products, and cosine similarity.
- Integrates with Python/NumPy and supports GPU execution.
- Disk storage of indexes for efficient use of resources.
Integrating Vector Databases for Enterprise
Vector databases are becoming an indispensable tool for businesses seeking to harness the power of their data in the age of AI and big data. With their exceptional ability to manage vast amounts of unstructured data and provide advanced search capabilities, these databases are crucial for applications requiring quick and accurate retrieval of information. The scalability of vector databases ensures they can adapt to growing data demands, while their integration with AI and machine learning models opens up new avenues for innovative applications. Additionally, their real-time processing capabilities are invaluable in scenarios where immediate data insights can offer a competitive edge.
Whether open-source or proprietary, vector databases offer unique features and benefits, making them a strategic choice for businesses looking to leverage the full potential of their data assets. As the technology continues to evolve, its role in shaping the future of data-driven decision-making and operations will only grow more significant.