
As AI takes the next leap forward with the introduction of NVIDIA Blackwell, data centers around the globe will need to take several key factors into consideration before deploying this behemoth of a GPU. Blackwell GPU promises a 30X increase in AI performance over its predecessor, the NVIDIA H100, setting a new standard for GPU power and efficiency. Slated for release in Q4 2024, NVIDIA Blackwell will create a significant shift for AI training and inference.
This leap in performance comes with substantial infrastructure requirements. Data centers looking to harness the full potential of NVIDIA Blackwell will likely need to undergo significant upgrades or even complete renovations. The scale of these upgrades encompasses everything from enhanced power per rack capable of supporting higher densities, to advanced cooling mechanisms to manage the increased heat output associated with powerful GPUs. Here is our top 5 considerations for businesses and data centers planning on deploying NVIDIA Blackwell.
1. Power Requirements
Current Power Landscape
Traditional data centers usually operate with a power density ranging from 4 to 6 kW per rack. However, with the rise of cloud and AI technologies, this density has increased, particularly for Cloud Service Providers (CSPs) and major internet companies such as Google or Meta, now see densities of 10 to 20 kW per rack (Dgtl Infra), and we are now seeing certain AI workloads exceeding 50-100 kW per rack.
Expected Power Needs for Blackwell
The NVIDIA Blackwell configurations are anticipated to require between 60kW to 120kW per rack, a substantial increase from traditional setups. However, this shift is not just a simple scale-up for many businesses, whether deploying on-prem or in a colocation, many data centers do not have rack power distribution capable of handling such high demands.
This requires a reevaluation of the entire power supply chain—from power generation and distribution to onsite power management and emergency power systems.
Challenges and Solutions
One major challenge is that fewer than 5% of current data centers in the world can support even 50kW per rack, highlighting a significant readiness gap for upcoming technologies like Blackwell (HPCwire). To bridge this gap, data centers will need to:
- Upgrade Electrical Infrastructure: This includes enhancing transformers, power distribution units (PDUs), and even the fundamental wiring to ensure they can handle increased loads without overheating or becoming safety hazards.
- Redesign Physical Layouts: Increased power densities may require physical alterations to data center designs, including changes to rack spacing, aisle layout, and possibly even the structural elements of the buildings to accommodate larger power feeds and cooling infrastructure.
- Monitor and Manage Power Use Dynamically: Utilizing AI and advanced monitoring technologies to optimize power usage and predict peak loads can help manage the increased power demands more efficiently. This proactive approach can reduce the risk of outages and improve overall energy efficiency.
The shift to NVIDIA Blackwell GPUs represents a significant technological advance but also poses substantial infrastructure challenges. By addressing these power requirements head-on, data centers can ensure they are ready to capitalize on the advantages these new GPUs offer.
2. Cooling Effectiveness
Increased Heat Output
The Blackwell GPUs are expected to operate with a thermal design power (TDP) of 400W to 1000W per GPU depending on the configuration. Traditional cooling methods, which have sufficed for lower-density racks, will likely be insufficient for these new demands. Current air cooling solutions are stressed under lesser loads and are inadequate for the intense heat generation anticipated with Blackwell GPUs.

Challenges in Traditional Cooling Systems
Traditional data centers are mostly equipped with air-based cooling systems designed for much lower power densities. For example, typical setups might only need to dissipate heat for power densities around 5-10 kW per rack. The introduction of GPU racks requiring over 60 kW will strain these systems beyond their designed capacities.
Transitioning to Advanced Cooling Technologies
- Liquid Cooling Implementation: Given the high thermal outputs of Blackwell GPUs, liquid cooling solutions are becoming essential. Unlike air cooling, liquid cooling can more efficiently absorb and dissipate heat due to its higher heat capacity and faster heat transfer properties. Implementing such systems involves integrating direct-to-chip cooling technologies or full immersion cooling setups, which can handle the thermal load more effectively but require significant infrastructure modifications including plumbing, pumps, and heat exchangers.
- Infrastructure Redesign for Cooling: Accommodating new cooling technologies will require data centers to rethink their physical layouts. This includes modifying or replacing existing HVAC systems and potentially redesigning the building's internal structure to accommodate larger cooling equipment and more complex distribution systems.
- Efficient Design and Placement: To maximize the efficiency of cooling systems, data centers must consider the placement of cooling infrastructure to optimize airflow and prevent hot spots. This might involve reorganizing rack layouts, optimizing aisle containment strategies, and even redesigning floor plans to better align with the new cooling systems' needs.
3. Space Management
Increased Rack Density Requirements
The higher energy consumption of NVIDIA Blackwell combined with the corresponding thermal output, means that traditional space allocations will be insufficient. For instance, given the high kW per rack requirements, data centers might find that a single rack can only accommodate one or two Blackwell systems without exceeding power and cooling capacities.

Transitioning to Efficient Layouts
To manage this increased density effectively, data centers need to:
- Optimize Rack Layouts: Reevaluate and possibly redesign rack configurations to support heavier power feeds and more robust cooling infrastructure. This might mean larger or more specialized racks that are spaced differently to allow for adequate cooling and maintenance access.
- Expand Physical Footprint: Facilities may need to expand their physical footprint or reconfigure existing spaces to accommodate the increased number of racks. This is particularly relevant in colocation environments where space is shared among various clients, and efficient use of space is critical.
- Modular Design Adoption: Implement modular data center designs that allow for rapid scalability and flexibility in configuration. This approach can accommodate the varying power and cooling needs of different clients, especially those utilizing high-density setups like those required for Blackwell GPUs.
Leveraging Space in On-Premise and Colocation Facilities
The reality of these new configurations means that both on-premise data centers and colocation facilities must plan for increased space per unit of compute capability. In colocation facilities, this could translate into higher costs for space rental, as clients may require more physical space to accommodate the higher density systems. On-premise facilities will need to consider potential expansions or more efficient use of existing space to avoid the excessive costs associated with physical expansion.
4. System Compatibility

Evaluating Existing Hardware
The introduction of Blackwell GPUs, designed to deliver unprecedented AI performance, requires a hardware environment capable of supporting their advanced features and power needs. Data centers will need to evaluate their current server hardware for compatibility with the GPU’s physical dimensions, power connectors, and thermal output.
- Server Evaluation: Verify that existing server chassis can accommodate the size and configuration of Blackwell GPUs. The DGX GB200 NVL72 uses an OCP-inspired design for its high-density configuration, but other Blackwell GPU configurations may fit into more conventional server racks. Each type of Blackwell configuration will have specific space and mounting requirements that must be matched with compatible server chassis and rack types.
- Interoperability: Interoperability between the new GPUs and existing network and storage systems must be ensured to avoid bottlenecks and maximize performance.
- Testing and Validation: Before full deployment, it’s crucial to conduct comprehensive testing to validate the compatibility and performance of the upgraded systems with Blackwell GPUs. At AMAX, we conduct thorough benchmarking tests to optimize the performance of the GPUs within the current infrastructure to identify potential issues or optimizations in power management, cooling, and data throughput.
5. Network Infrastructure
Challenges in Traditional Network Systems
Most current data centers are equipped with network systems designed for moderate data flows, typical of earlier hardware. Standard configurations might only support 50 Gb/s to 100 Gb/s per connection, sufficient for traditional computing tasks but inadequate for the high-speed data transfer requirements of AI and advanced GPUs like Blackwell, which operates with 400 Gb/s to 800 Gb/s with the new NVIDIA Quantum-X800 InfiniBand Platform.
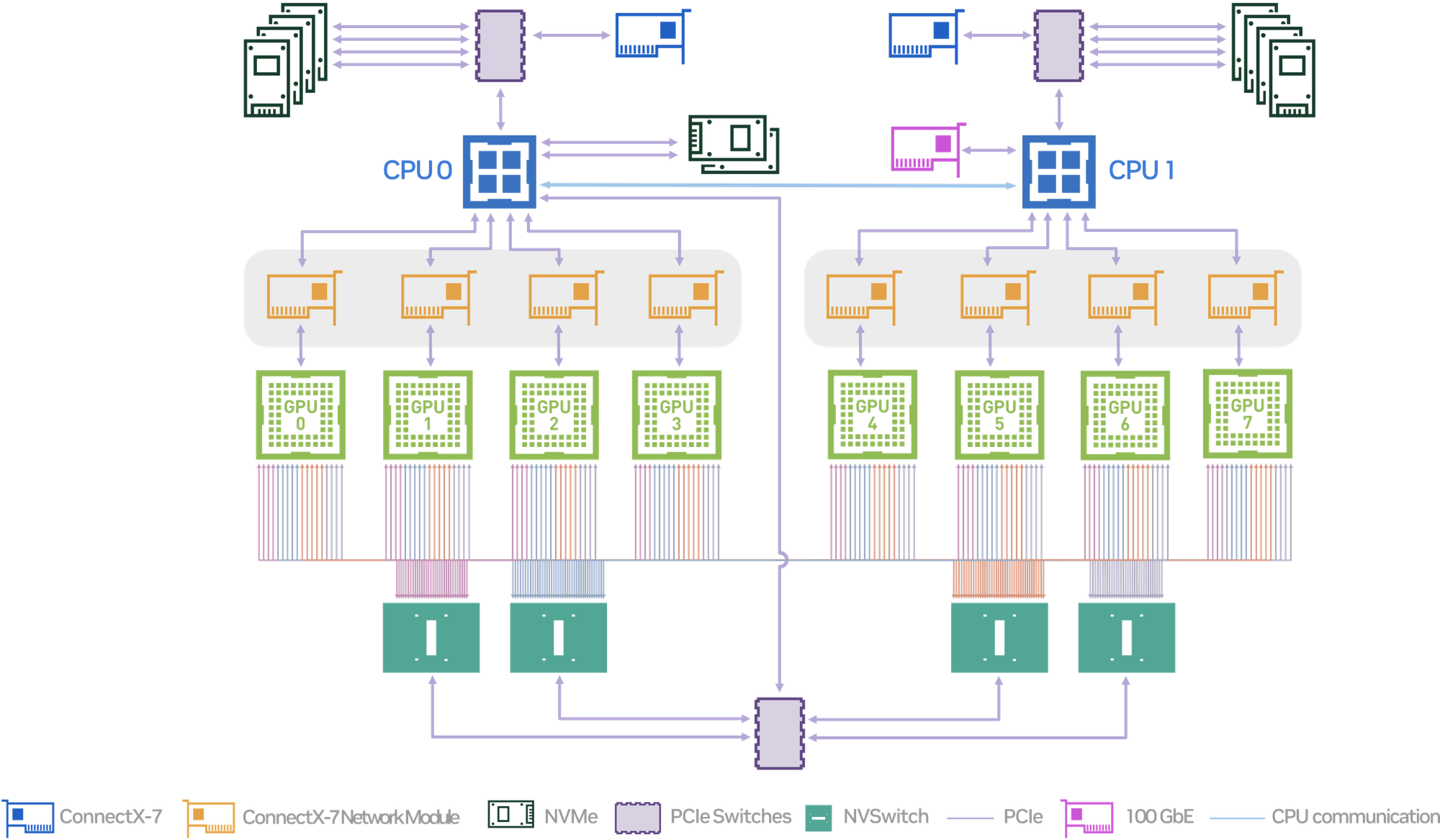
Transitioning to High-Speed Network Technologies
- High-Bandwidth Switches: With Blackwell's high data throughput demands, upgrading to high-bandwidth switches and routers becomes essential. These devices must be capable of handling significantly higher data rates, supporting 400 Gb/s or more with the 5th generation NVIDIA NVLink to facilitate rapid data exchange and processing across the network.
- Advanced Network Architecture Implementation: Adopting modern network topologies such as spine-leaf or fat-tree network architectures can dramatically improve data flow efficiency within data centers. This topology reduces latency and manages higher bandwidth more effectively, crucial for operations involving high-density GPU deployments.
- Ensuring Network Redundancy and Resilience: To maintain constant uptime and reliability, it is critical to integrate redundancy into the network design. This involves setting up redundant pathways and failover mechanisms to ensure that the network remains operational even if one part fails, providing continuous service for AI and machine learning computations.
Getting Ready for NVIDIA Blackwell with AMAX
The release of NVIDIA Blackwell GPUs marks a pivotal advancement in artificial intelligence technology, demanding readiness and adaptability from data centers worldwide. This evolution compels facilities to rethink their existing infrastructures and envision future capabilities and growth.
As organizations prepare to integrate these powerful GPUs, the focus should not solely be on meeting immediate technical requirements but also on strategic planning for scalability and future technological integrations. Engaging with experts and leveraging advanced engineering support will be crucial in ensuring that data centers not only keep pace with current technological advancements but are also poised to lead in the era of next-generation AI computing.