
NVIDIA Unveils New Blackwell GPU Architecture
NVIDIA announced at GTC 2024, its newest GPU architecture NVIDIA Blackwell offering the capability to operate real-time generative AI on large language models with trillions of parameters at 25x less cost and energy consumption.

Innovations Driving the Future of AI and Computing
The Blackwell platform encompasses several technological innovations:
- World’s Most Powerful Chip: With 208 billion transistors, these GPUs leverage a custom-built 4NP TSMC process. They feature a chip-to-chip link with a 10 TB/second throughput, forming a unified GPU structure.
- Second-Generation Transformer Engine: Enhanced with micro-tensor scaling support and advanced algorithms, Blackwell doubles the compute and model sizes, introducing new AI inference capabilities.
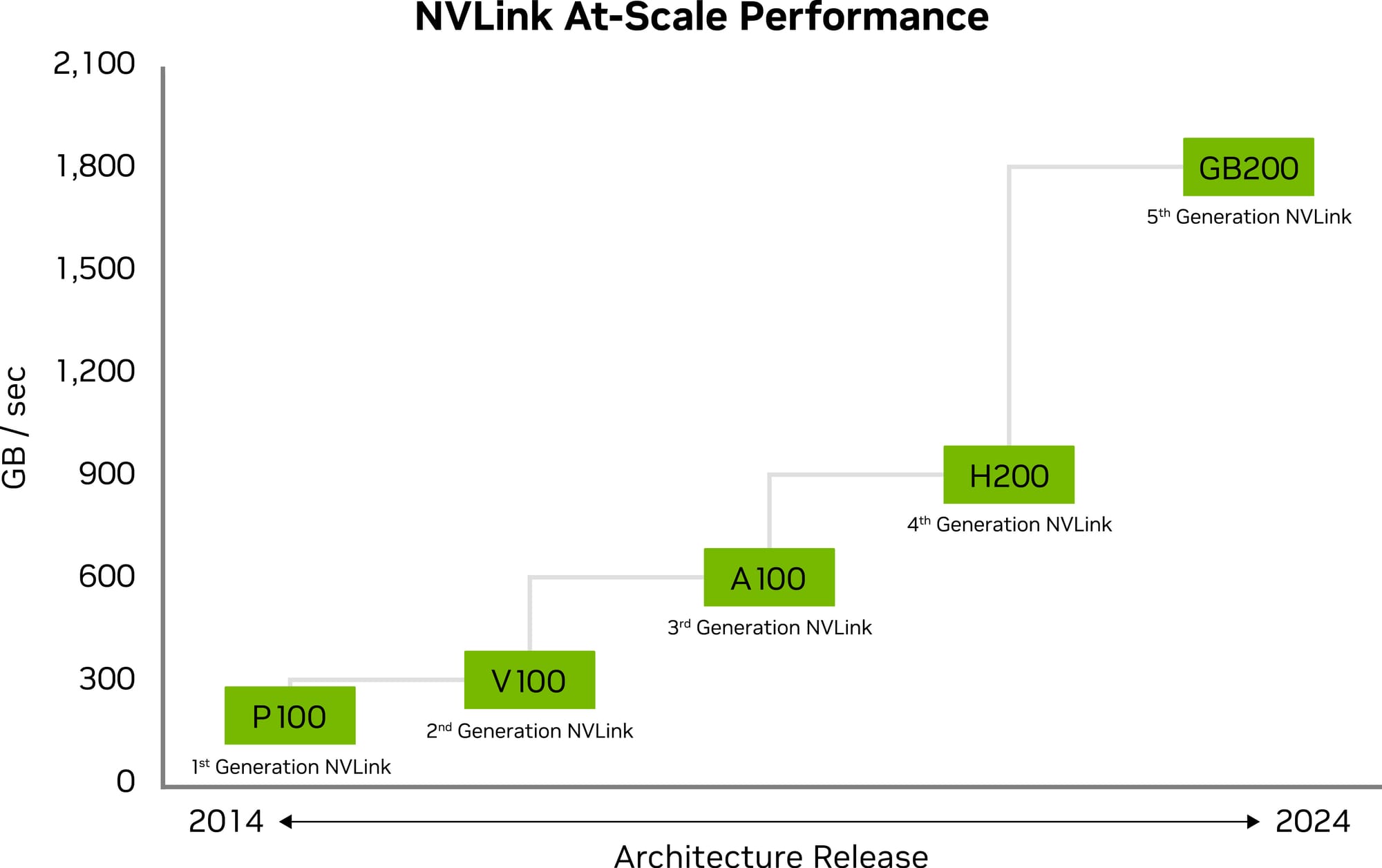
- Fifth-Generation NVLink: This latest version delivers 1.8TB/s bidirectional throughput per GPU, facilitating communication among up to 576 GPUs for complex model computations.
- RAS Engine: Dedicated to reliability, availability, and serviceability, this engine uses AI for preventative maintenance, enhancing system uptime and reducing operating costs.
- Secure AI: Offers advanced confidential computing to safeguard AI models and customer data, supporting new encryption protocols for industries requiring strict privacy measures.
- Decompression Engine: This engine accelerates database queries, enhancing performance in data analytics and science, crucial for GPU-accelerated data processing.

The NVIDIA GB200 Grace Blackwell Superchip
The NVIDIA GB200 Grace Blackwell Superchip connects two B200 Tensor Core GPUs to the Grace CPU via a 900GB/s NVLink. When paired with NVIDIA's Quantum-X800 InfiniBand and Spectrum™-X800 Ethernet platforms, it achieves unparalleled AI performance.

Moreover, the GB200 is integral to the NVIDIA GB200 NVL72, a liquid-cooled, rack-scale system designed for intensive compute workloads. This system showcases a remarkable 30x performance increase for LLM inference workloads, significantly lowering cost and energy usage.

NVIDIA's HGX B200 server board, which links eight B200 GPUs, is optimized for x86-based generative AI platforms, supporting networking speeds of up to 400Gb/s. This innovation underscores NVIDIA's commitment to enhancing AI capabilities and efficiency across industries, promising a new era of computing.
Fifth-Generation NVLink
The scalability of multi-GPU systems has received a significant boost with the fifth generation of NVLink. It allows a single NVIDIA Blackwell Tensor Core GPU to support up to 18 connections at 100 gigabytes per second each, culminating in a total bandwidth of 1.8 terabytes per second. This enhancement doubles the bandwidth available in the previous generation and surpasses PCIe Gen5 bandwidth by more than 14 times. Server platforms leveraging this technology, such as the GB200 NVL72, can now offer unprecedented scalability for complex large models.
The NVLink Switch Chip is a game-changer, fully enabling GPU-to-GPU connections with a 1.8TB/s bidirectional, direct interconnect. This setup scales multi-GPU input and output within a server, and the NVLink Switch chips link multiple NVLinks, facilitating all-to-all GPU communication at full NVLink speed both within and between racks. Each NVLink Switch also integrates engines for NVIDIA's Scalable Hierarchical Aggregation and Reduction Protocol (SHARP)™, accelerating in-network reductions and multicast operations, essential for high-speed collective tasks.
NVIDIA DGX GB200 NVL72
The NVIDIA DGX GB200 NVL72, connects two high-performance NVIDIA Blackwell Tensor Core GPUs and the NVIDIA Grace CPU with the NVLink-Chip-to-Chip (C2C) interface that delivers 900 GB/s of bidirectional bandwidth. With NVLink-C2C, applications have coherent access to a unified memory space.

The NVIDIA DGX GB200 NVL72 offers 36 Grace CPUs and 72 Blackwell GPUs within a single rack-scale design. The liquid-cooled, exaflop-per-rack solution delivers unprecedented real-time capabilities for trillion-parameter large language models (LLMs), setting a new benchmark in the industry.
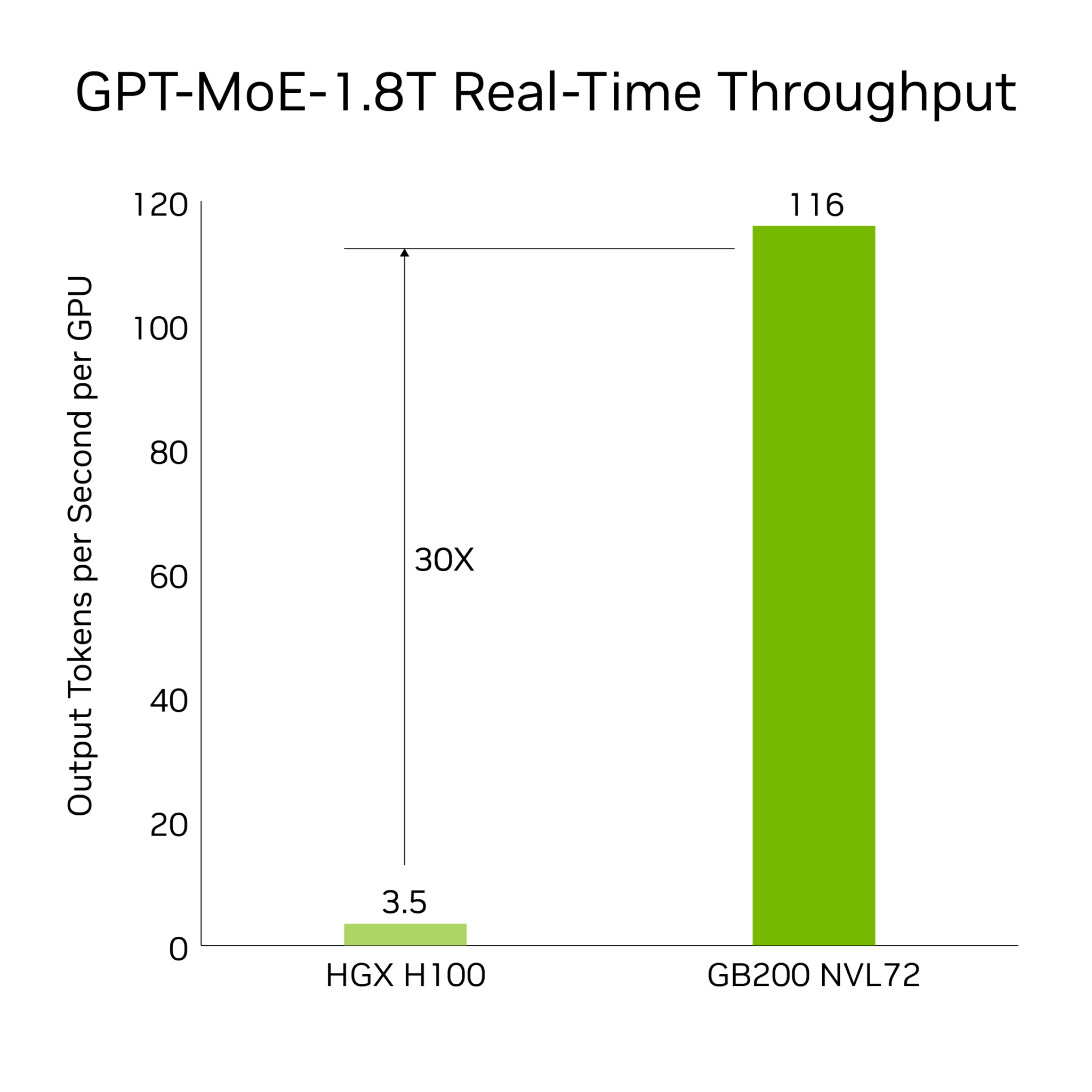
NVIDIA's GB200 NVL72 redefines what's possible with exascale computing, offering the largest NVLink® domain to date. This enables 130 terabytes per second (TB/s) of low-latency GPU communication, catering to the most demanding AI and high-performance computing (HPC) workloads.
Specifications
| Specification | GB200 NVL72 | GB200 Grace Blackwell Superchip |
|---|---|---|
| Configuration | 36 Grace CPU : 72 Blackwell GPUs | 1 Grace CPU : 2 Blackwell GPU |
| FP4 Tensor Core | 1,440 PFLOPS | 40 PFLOPS |
| FP8/FP6 Tensor Core | 720 PFLOPS | 20 PFLOPS |
| INT8 Tensor Core | 720 POPS | 20 POPS |
| FP16/BF16 Tensor Core | 360 PFLOPS | 10 PFLOPS |
| TF32 Tensor Core | 180 PFLOPS | 5 PFLOPS |
| FP64 Tensor Core | 3,240 TFLOPS | 90 TFLOPS |
| GPU Memory | Bandwidth | Up to 13.5 TB HBM3e | 576 TB/s | Up to 384 GB HBM3e | 16 TB/s |
| NVLink Bandwidth | 130TB/s | 3.6TB/s |
| CPU Core Count | 2,592 Arm® Neoverse V2 cores | 72 Arm Neoverse V2 cores |
| CPU Memory | Bandwidth | Up to 17 TB LPDDR5X | Up to 18.4 TB/s | Up to 480GB LPDDR5X | Up to 512 GB/s |
{kind=link}