
To achieve the maximum capabilities of exascale computing and AI models with trillion-scale parameters, rapid and efficient communication across all GPUs within a server cluster is essential. The fifth generation of NVLink serves as an advanced scale-up interconnect, driving enhanced performance for AI models with trillion and multi-trillion parameters and will be implemented in the NVIDIA DGX GB200 NVL72.
Bridging the Gap in High-Speed Communication
The NVLink and NVLink Switch are designed to serve as the foundational blocks for high-speed, multi-GPU communication. This technology is crucial for feeding large datasets more swiftly into models and facilitating rapid data exchange between GPUs. The advent of fifth-generation NVLink introduces a scale-up interconnect that propels accelerated performance for AI models with trillion and multi-trillion parameters, addressing the growing demand for faster scale-up interconnects in server clusters.
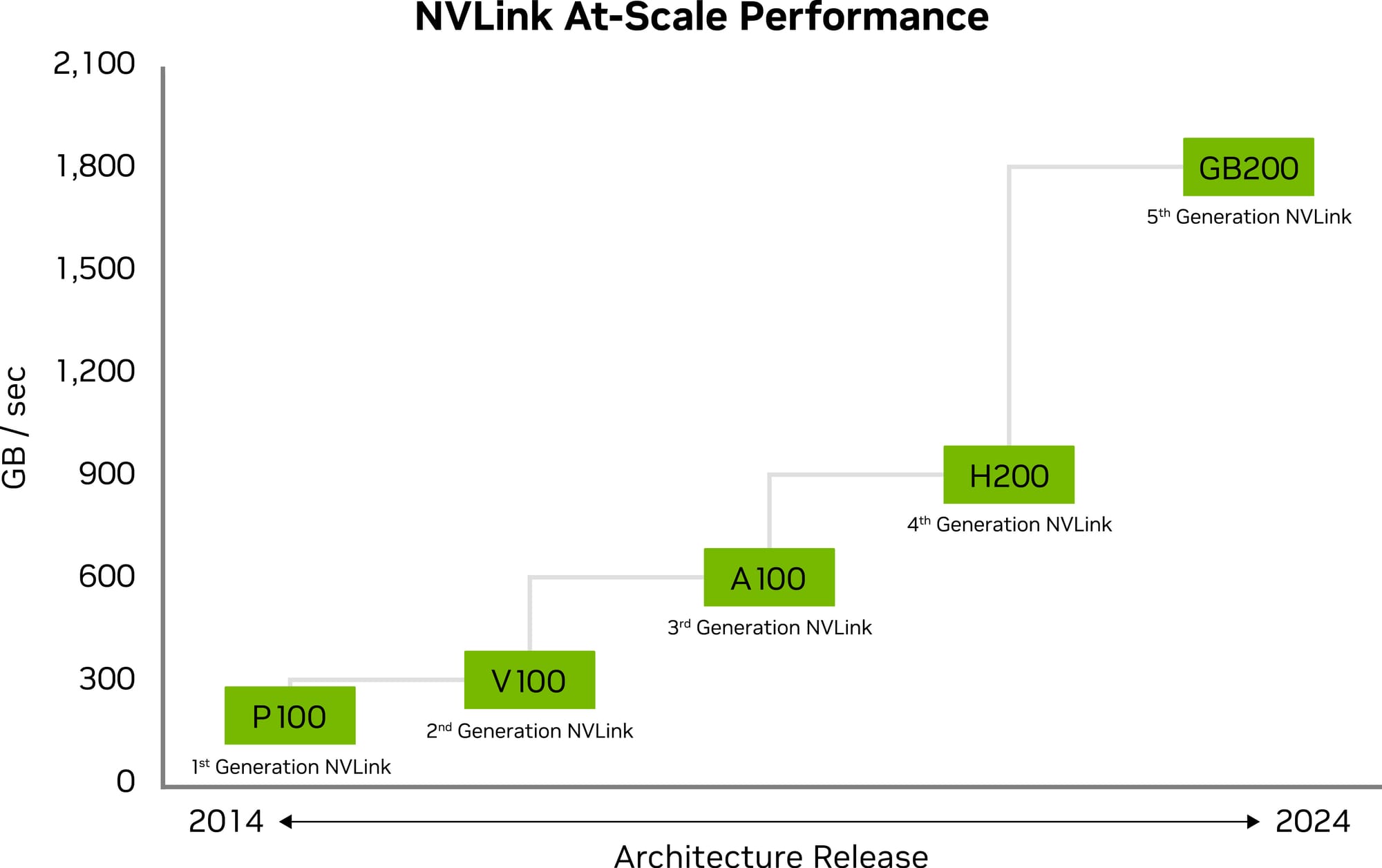
Maximizing Throughput with NVIDIA NVLink
The scalability of multi-GPU systems has received a significant boost with the fifth generation of NVLink. It allows a single NVIDIA Blackwell Tensor Core GPU to support up to 18 connections at 100 gigabytes per second each, culminating in a total bandwidth of 1.8 terabytes per second. This enhancement doubles the bandwidth available in the previous generation and surpasses PCIe Gen5 bandwidth by more than 14 times. Server platforms leveraging this technology, such as the GB200 NVL72, can now offer unprecedented scalability for complex large models.

Enhancing GPU Communications with NVLink Switch
The NVLink Switch Chip is a game-changer, fully enabling GPU-to-GPU connections with a 1.8TB/s bidirectional, direct interconnect. This setup scales multi-GPU input and output within a server, and the NVLink Switch chips link multiple NVLinks, facilitating all-to-all GPU communication at full NVLink speed both within and between racks. Each NVLink Switch also integrates engines for NVIDIA's Scalable Hierarchical Aggregation and Reduction Protocol (SHARP)™, accelerating in-network reductions and multicast operations, essential for high-speed collective tasks.

Training Multi-Trillion Parameter Models
NVLink Switch technology extends NVLink connections across nodes, creating a seamless, high-bandwidth, multi-node GPU cluster. This effectively turns a data center into a giant GPU, with the NVIDIA NVLink Switch enabling 130TB/s of GPU bandwidth in an NVL72 setup for large model parallelism. As a result, multi-server clusters with NVLink can scale GPU communications to match the surge in computing capabilities, supporting up to nine times more GPUs than a conventional eight-GPU system.
The Pinnacle of AI and HPC Platforms
NVIDIA's NVLink and NVLink Switch form the backbone of the most powerful AI and HPC platform to date. This comprehensive data center solution includes hardware, networking, software, libraries, and optimized AI models and applications from NVIDIA's AI Enterprise software suite and the NVIDIA NGC™ catalog. It stands as the ultimate platform for researchers to achieve groundbreaking results and deploy solutions into production, facilitating unprecedented acceleration at every scale.
Specifications
| Feature | First Generation | Second Generation | Third Generation | NVLink Switch |
|---|---|---|---|---|
| Number of GPUs with direct connection within a NVLink domain | Up to 8 | Up to 8 | Up to 8 | Up to 576 |
| NVSwitch GPU-to-GPU bandwidth | 300GB/s | 600GB/s | 900GB/s | 1,800GB/s |
| Total aggregate bandwidth | 2.4TB/s | 4.8TB/s | 7.2TB/s | 1PB/s |
| Supported NVIDIA architectures | NVIDIA Volta™ architecture | NVIDIA Ampere architecture | NVIDIA Hopper™ architecture | NVIDIA Blackwell architecture |