
Enterprises that are developing systems to run intense AI workloads have two choices to do the heavy lifting: traditional CPU (central processing unit) architecture, or a specialized GPU (graphics processing unit) pipeline. It’s almost universally understood that in the modern enterprise context, running numerous deep learning workloads in parallel is the bread and butter of GPUs. However, it’s important to clearly understand the full extent of AI/deep learning applications and how to choose the right type of processor for a given workload.
CPU and GPU: How They Work
CPUs are designed to prioritize operational speed for sequential calculations, which allows them to perform diverse instruction sets. When assigned the right task, CPUs perform with outstanding quickness, measured by the clock speed. Today, the CPU is still the core part of any computing device. It handles basic instructions and allocates the more complicated tasks to other specific chips on the motherboard. Note that a GPU is not a substitute for a CPU.
A GPU is designed to quickly render high-resolution 2D/3D images, video, visualization and display. GPUs began as graphics pipelines, but their use has evolved into one of the core components of deep learning/AI. GPUs are designed to efficiently handle bulk operations performed in parallel. They are engineered with vastly more numerous computing cores than CPUs, which is an ideal architecture for repetitive, highly-parallel and unique computing tasks.
The main difference between CPU and GPU architecture is that a CPU is designed to quickly handle a wide-range of complex computations measured by CPU clock speed, and GPUs are designed to quickly handle many concurrent simple and specific tasks. CPUs have less cores with high processing speeds. GPUs have thousands of cores and have comparatively slower speeds than CPUs. Because GPUs have more cores and can perform parallel operations on multiple sets of data, they more than catch up to the processing speeds commonly needed for non-graphical tasks, such as machine learning and scientific computation.
When Are GPUs Used?
GPUs are ideal for parallel processing and have become preferred for training AI models: they perfectly match the needs for a process that requires largely identical operations simultaneously performed on all data samples. Data set sizes are growing almost exponentially, and the massive parallelism provided by GPUs results in faster performance of these tasks.
GPUs are designed to excel in applications that require processing of numerous calculations in parallel, which is the overwhelming share of enterprise AI applications:
- Accelerated deep learning and AI operations with massive parallel data inputs
- Traditional AI training and inference algorithms
- Classical neural networks
In short, when raw computational power for processing unstructured or largely identical data is required, GPUs are the preferred solution.
Take for example the new A100 GPU from Nvidia. The A100 features NVIDIA’s first 7nm GPU, the GA100. This GPU is equipped with 6912 CUDA cores and 40GB of HBM2 memory. This GPU is also on the first card featuring PCIe 4.0 interface in addition to the SXM4 form factor, and it is just as fast. Because the PCIe version has lower power consumption (250W vs. 400W in the SXM4 counterpart), expect to take a 10% performance hit. However, that is quickly earned back in terms of lower power and cooling expenses. The GA100 graphics processor is a large chip with a die area of 826 mm² and 54.2 billion transistors. It features 6912 shading units, 432 texture mapping units, and 160 ROPs. Also included are 432 tensor cores, which help improve the speed of machine learning applications. NVIDIA has paired 40 GB HBM2E memory with the A100 SXM4, which are connected using a 5120-bit memory interface. The GPU operates at a frequency of 1410 MHz, and memory runs at 1215 MHz. The A100 is optimized for tensor operations, including the new higher precision TF32 and FP64 formats, and lower 8-bit precision computations for inference.
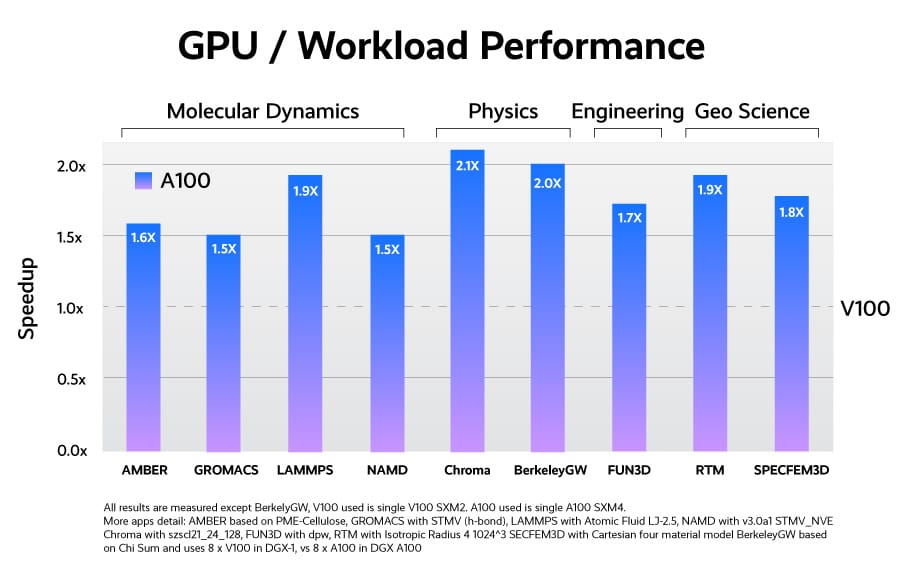
The A100 GPU realizes a 250% advantage over its previous 12nm Volta GPU in peak double precision floating point performance. In HPC workloads, realized speedups ranged between 1.5X and 2.1X compared to its predecessor.
GPUs have evolved significantly compared to 30 years ago, when they were primarily used in personal computers. As performance and densities increased, it has transitioned into professional workstations, then to servers, and now into data center rack pods. As more applications run in the cloud and datacenters, expect GPUs to be an essential element of architecture and systems. Growing GPU power is demonstrated by the Nvidia A100 GPU, which can be sliced into 7 separate instances (multi-instance GPU) so that it can drive improved utilization of GPU processing and provisioning of various workloads in the datacenter.
When Are CPUs Used?
The use case for CPUs in enterprise AI roles is narrower and more specialized. Tasks that heavily feature algorithms that are difficult to run in parallel may be better suited for CPUs, including:
- Training and inference recommender systems that require larger memory for embedding layers
- Machine learning and real-time inference algorithms that do not parallelize easily
- Recurrent neural networks that rely on sequential data
- Large-size data sample models, including 3D data for training and inference
CPUs are better suited to tasks that utilize sequential algorithms and for performing complex statistical computations, however these types of tasks are less common in enterprise AI applications today. Most enterprises prefer the speed and efficiency of GPUs, rather than the specialization of CPUs. However, there are data scientists that are rethinking the way AI algorithms are developed, to potentially rely on logic (serial processing) rather than statistical computations.
The CPU is the master of the system, specifically designed to allow it to plan and enforce scheduling for all system components and the clock speeds of the cores. This makes them good at performing single, complex math problems in a short time. When performing many, many small tasks at once, such as rendering 300,000 triangles and dynamically transforming them on demand, CPUs begin to show their limitations, especially in ResNet neural network calculations.
The number of cores in a processor are increasing. These processors within a processor have between 2 to 64 cores. The AMD Ryzen Threadripper 3970X has 32 cores capable of processing 64 threads. The AMD Epyc 7702 has 64 cores and 128 threads. The benefit of having multiple cores is that the system can handle more separate streams of data or threads that run independent of each other. This architecture greatly increases the resources and performance of a system that is running concurrent applications and multiple tasks in the data center. More and more developers are exploring the complexity of writing code to perform in parallel multi-threaded computing, virtualized and containerized environments.
CPUs and GPUs Together
In data centers, it is essential to take advantage of both CPUs and GPUs. Moore’s Law is slowing, and as such, to scale up and out, the overall performance of systems will need to depend on a complete ecosystem of hardware, software, and developers. AI workloads will demand a variety of silicon technologies, and these solutions will need to bring together purpose built processors and general purpose processors into these servers and devices to achieve better performance, efficiency and costs – from the data center to the edge.
NVIDIA’s high-bandwidth, energy-efficient interconnect enables ultra-fast CPU to GPU and GPU to GPU communication. AMAX servers take advantage of GPU to GPU communication. The SXM4 design allows GPUs to operate beyond the restrictions of the PCIe bus so they can reach their maximum performance potential. To increase IO between GPUs, Nvidia NVLink provides a high-speed path between them, allowing them to communicate at peak data rates of 300 gigabytes per second (GB/s), a speed 10x faster than PCIe. Unlike PCIe, with NVLink a device has multiple paths to choose from, and rather than share a central hub to communicate, they instead use a mesh that enables the highest bandwidth data interchange between GPUs. This significantly speeds up applications and delivers greater raw computing performance than GPUs using PCIe. By increasing the total bandwidth between the GPU and other parts of the system, the data flow and total system throughput are improved to enhance the performance of the workloads. In the cloud data center, GPUs are treated as a peripheral used by CPU cores.
Understand Your Workload to Understand Your Processing Needs
Enterprise AI and deep learning workloads are diverse and many-faceted operations. Choosing whether to build your computational pipeline with GPUs and/or CPUs requires understanding your anticipated workloads and computing environment: success is defined by matching the right processor to your applications. As in all business decisions, choosing the right tool for the job is critical to reaching your performance goals.