
One Giant GPU
Introducing NVIDIA DGX GB200, a liquid-cooled, rack-scale solution connecting 72 high-performance NVIDIA Grace Blackwell Superchips with NVLink to deliver customers a massive unified memory space.
NVIDIA DGX GB200 is powered by 36 Grace CPUs and 72 Blackwell GPUs within a single rack. The liquid-cooled, exaflop-per-rack solution delivers unprecedented real-time capabilities for trillion-parameter large language models (LLMs), setting a new benchmark in the industry.
Unlocking Real-Time Trillion-Parameter Models
- Enhanced Natural Language Processing (NLP): These models excel in complex NLP tasks including translation, question answering, summarization, and improving language fluency.
- Improved Contextual Understanding: They are capable of maintaining extended conversational context, significantly advancing chatbots and virtual assistant technologies.
- Multimodal Applications: By integrating language, vision, and speech, these models unlock new possibilities in AI's ability to understand and interact with the world.
- Creative and Generative AI: From generating stories and poetry to coding, these models are fueling a new era of creative AI applications.
- Scientific Breakthroughs: Their application in fields like protein folding and drug discovery is accelerating scientific research and innovation.
- Advanced Personalization: Trillion-parameter models can develop unique personalities and remember individual user contexts, offering personalized experiences like never before.
NVIDIA DGX GB200

NVIDIA DGX GB200 houses 72 GPUs. . Each rack contains 18 compute trays that hold 2 Grace Blackwell Superchips, all interconnected with an NVLink Switch System.
For efficient operations, DGX GB200 utilizes a copper cable cartridge to connect GPUs tightly. This model also incorporates a liquid cooling system that significantly reduces costs and energy use by 25 times.
Fifth-generation NVLink and NVLink Switch System
NVIDIA DGX GB200 features the latest, fifth-generation NVLink technology, enabling connectivity for up to 576 GPUs within a single NVLink domain. This setup boasts a total bandwidth surpassing 1 petabyte per second and supports 240 terabytes of rapid access memory. Each NVLink switch tray is equipped with 144 NVLink ports, each offering 100 GB of bandwidth, allowing nine switches to interconnect the 18 NVLink ports found on each of the 72 Blackwell GPUs.

This model achieves an impressive 1.8 terabytes per second of bidirectional throughput for each GPU, marking more than a fourteenfold increase over the bandwidth provided by PCIe Gen5. This ensures high-speed, efficient communication for handling the most demanding large-scale models of today.
Exascale Computing in a Single Rack
NVIDIA's DGX GB200 redefines what's possible with exascale computing, offering the largest NVLink® domain to date. This enables 130 terabytes per second (TB/s) of low-latency GPU communication, catering to the most demanding AI and high-performance computing (HPC) workloads.
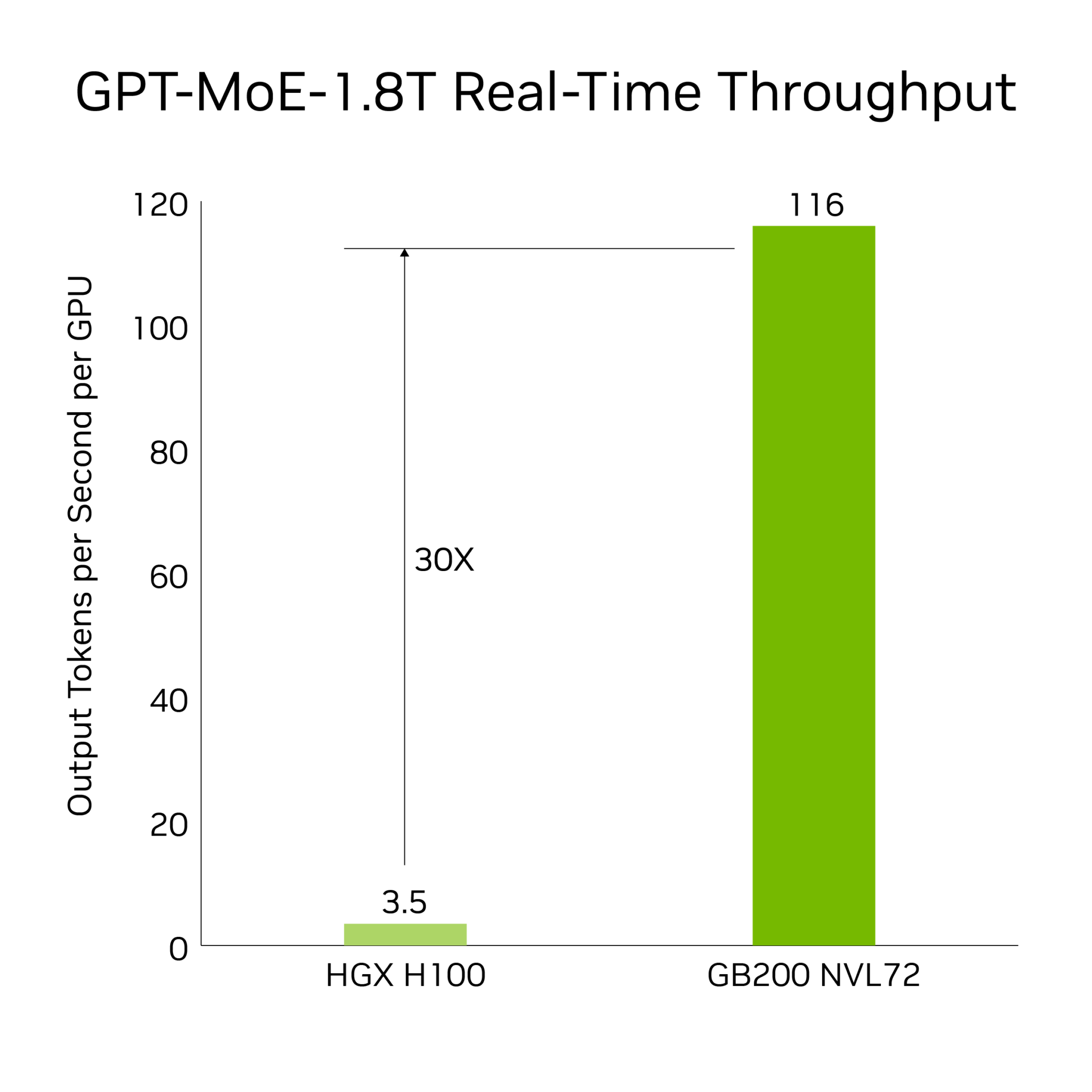
Key Highlights
- Next-Generation AI and Accelerated Computing: DGX GB200 excels in LLM inference, training, energy efficiency, and data processing, showcasing significant improvements over previous generation systems.
- Innovative Architecture: The NVIDIA Blackwell architecture introduces new Tensor Cores and microscaling formats, enhancing accuracy and throughput for AI applications.
- Energy-Efficient Infrastructure: Through its liquid-cooled design, the DGX GB200 significantly reduces energy consumption and carbon footprint, offering 25X more performance at the same power usage compared to air-cooled alternatives.
- Enhanced Data Processing: Leveraging high-bandwidth memory and dedicated decompression engines, the DGX GB200 speeds up database queries significantly, demonstrating a profound impact on enterprise data handling and analysis.
Specifications
| Specification | DGX GB200 | GB200 Grace Blackwell Superchip |
|---|---|---|
| Configuration | 36 Grace CPU : 72 Blackwell GPUs | 1 Grace CPU : 2 Blackwell GPU |
| FP4 Tensor Core | 1,440 PFLOPS | 40 PFLOPS |
| FP8/FP6 Tensor Core | 720 PFLOPS | 20 PFLOPS |
| INT8 Tensor Core | 720 POPS | 20 POPS |
| FP16/BF16 Tensor Core | 360 PFLOPS | 10 PFLOPS |
| TF32 Tensor Core | 180 PFLOPS | 5 PFLOPS |
| FP64 Tensor Core | 3,240 TFLOPS | 90 TFLOPS |
| GPU Memory | Bandwidth | Up to 13.5 TB HBM3e | 576 TB/s | Up to 384 GB HBM3e | 16 TB/s |
| NVLink Bandwidth | 130TB/s | 3.6TB/s |
| CPU Core Count | 2,592 Arm® Neoverse V2 cores | 72 Arm Neoverse V2 cores |
| CPU Memory | Bandwidth | Up to 17 TB LPDDR5X | Up to 18.4 TB/s | Up to 480GB LPDDR5X | Up to 512 GB/s |