

As NVIDIA phases out the NVIDIA A100 Tensor Core GPU, it's crucial for organizations in AI and high-performance computing to consider next-generation alternatives. This article offers a detailed comparison between the NVIDIA H100 Tensor Core GPU and the NVIDIA A100, highlighting the enhanced capabilities and use cases of the H100 as an upgrade to your data center operations.
To explore an alternative option for the A100, we invite you to read our in-depth comparison article on A100 vs L40S for additional insights. Understanding these differences is key to making informed decisions for future-ready AI and computing infrastructures.
NVIDIA H100 Overview
The NVIDIA H100 offers remarkable capabilities for AI and high-performance computing. This powerful GPU is available in two primary form factors: SXM and PCIe, each designed to meet specific needs and integration requirements. To see how the NVIDIA H100 compares to the NVIDIA H200 view our in-depth comparison.
NVIDIA DGX™ H100 and NVIDIA HGX™ H100

The NVIDIA H100 Tensor Core GPU is at the heart of NVIDIA's DGX H100 and HGX H100 systems. The DGX H100, known for its high power consumption of around 10.2 kW, surpasses its predecessor, the DGX A100, in both thermal envelope and performance, drawing up to 700 watts compared to the A100's 400 watts. The system's design accommodates this extra heat through a 2U taller structure, maintaining effective air cooling.
The HGX H100, on the other hand, is tailored for cloud providers and system manufacturers, offering 4- and 8-GPU configurations. This versatility allows for the construction of custom H100 systems and clusters, catering to a range of cloud and enterprise needs.
SXM and PCIe NVIDIA H100 Models
The H100 SXM model is integral to both the DGX and HGX systems, featuring in the standardized 8x SXM GPU platform. This model is especially beneficial for server vendors, as it allows them to purchase a complete GPU assembly directly from NVIDIA, ensuring optimal GPU performance and heat management.
The H100 is also available in a PCIe form factor, catering to a broader range of server configurations and offering flexibility for various computing environments. This model is especially useful for organizations seeking to integrate the H100 into existing server architectures without the need for a complete system overhaul.
NVIDIA H100 Applications
- Generative AI Applications:
- The H100 GPU excels in the field of generative AI, offering the processing power necessary for developing innovative services, generating new insights, and creating original content. It's particularly useful in sectors such as digital marketing, creative arts, and AI-driven content generation.
- Large Language Model (LLM) Training and Inference:
- Ideal for businesses delving into the expanding realm of natural language processing, the H100 provides ample resources for training and deploying large language models. This makes it a valuable asset in applications like automated customer support, language translation services, and sentiment analysis tools.
- Healthcare and Medical Research:
- The H100 plays a pivotal role in healthcare and life sciences, particularly in areas like medical imaging analysis, genomic sequencing, and drug discovery. Its computational power aids in faster and more accurate data processing, contributing to advancements in medical research and diagnostics.
NVIDIA A100 Overview
The NVIDIA A100, harnessing the power of the NVIDIA Ampere architecture, was designed to accelerate AI, data analytics, and high-performance computing (HPC). The A100 delivers was available in various form factors, including PCIe and SXM, to fit diverse deployment needs.
NVIDIA DGX™ A100 and NVIDIA HGX™ A100

Central to NVIDIA's DGX A100 and HGX A100 systems, the A100 GPU was renowned for its robust computational abilities however has been surpassed by the H100. The DGX A100 integrates eight NVIDIA A100 Tensor Core GPUs, offering unmatched acceleration and optimized for NVIDIA CUDA-X software. In contrast, the HGX A100 is tailored for cloud services and large-scale data centers, providing scalable and powerful computing solutions.
PCIe and SXM NVIDIA A100 Models
- PCIe Model: The A100 in PCIe form factor is versatile for a wide range of server configurations, making it ideal for integrating into various computing environments without extensive system modifications.
- SXM Model: Featured in the HGX and DGX systems, the A100 SXM model is part of NVIDIA's standardized GPU platform, offering server vendors the opportunity to integrate a complete and high-performance GPU solution.
NVIDIA A100 Applications
- AI Training and Inference:
- For AI inference, the A100 accelerates a range of precision levels, from FP32 to INT4, and supports Multi-Instance GPU technology for efficient resource utilization.
- Financial Analytics:
- The A100 is crucial in financial sectors, enhancing risk management models, algorithmic trading, and real-time financial data analysis.
- Autonomous Vehicles and Robotics:
- The A100 supports the development and operation of autonomous systems and robotics, providing the computational power necessary for real-time decision-making and sensor data processing.
NVIDIA H100 vs NVIDIA A100 Architecture Comparison
Tensor Cores are NVIDIA's revolutionary compute cores, optimized for matrix multiply and accumulate (MMA) operations. They are instrumental in providing exceptional performance for AI and HPC (High-Performance Computing) applications. By operating in parallel across the Streaming Multiprocessors (SMs) within a single NVIDIA GPU, Tensor Cores significantly boost throughput and efficiency beyond traditional floating-point (FP), integer (INT), and fused multiply-accumulate (FMA) operations.
Introduced with the NVIDIA V100 GPU, Tensor Cores have seen continuous enhancements with each subsequent NVIDIA GPU generation.
The latest iteration in the H100, the fourth-generation Tensor Core architecture (NVIDIA Hopper™ architecture), brings notable advancements:
- Enhanced Matrix Math Throughput: Each SM in the H100 offers double the dense and sparse matrix math throughput compared to the A100, maintaining the same clock speed. This improvement is even more pronounced when factoring in the H100's higher GPU Boost clock relative to the A100.
- Diverse Data Type Support: The Tensor Cores support a wide range of data types for MMA operations, including FP8, FP16, BF16, TF32, FP64, and INT8. This versatility allows for broader application across various computational tasks.
- Efficient Data Management: The redesigned Tensor Cores in the H100 feature improved data management capabilities. They are more power-efficient in delivering operands, achieving up to a 30% reduction in operand delivery power.
NVIDIA H100 vs NVIDIA A100 Performance Comparison
The NVIDIA H100 with InfiniBand interconnect significantly outperforms its predecessor, delivering up to 30 times the performance of the A100. For computing workloads that demand model parallelism across multiple GPU-accelerated nodes, the NVLink Switch System interconnect is particularly effective. These workloads see an additional performance leap with the H100, in some cases tripling the performance yet again over the H100 with InfiniBand.
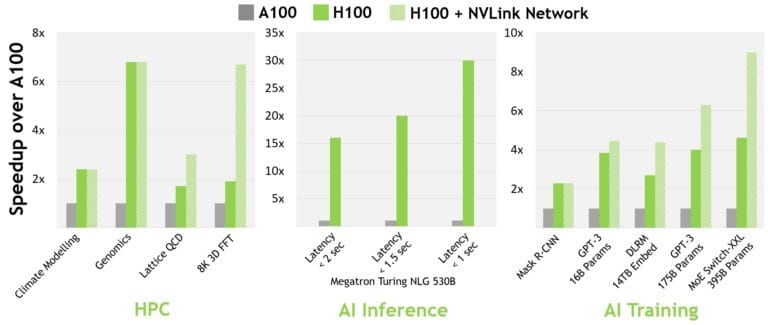
A comparative analysis using from 8 to 256 H100 GPUs demonstrates the H100's capacity for enabling next-generation AI and HPC breakthroughs. Preliminary performance numbers, based on current expectations and subject to change in shipping products, reveal significant advancements in a variety of applications. For instance, in climate modeling, genomics, 3D-FFT, and various large-scale AI models, the H100 shows a substantial increase in processing speed and efficiency compared to clusters equipped with A100 GPUs.
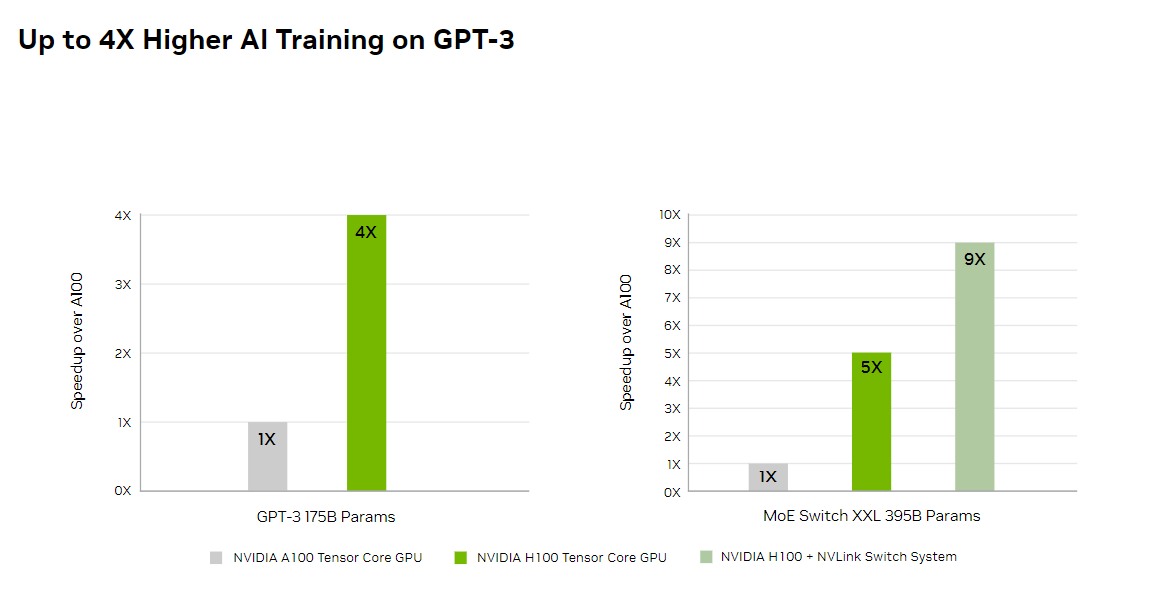
In specific terms, the H100 cluster, leveraging the NDR IB network with NVLink Switch System where indicated, achieves notable performance gains in tasks such as large model training and complex data analysis. This demonstrates the H100's ability to handle more demanding AI and HPC tasks with greater speed and efficiency.
NVIDIA H100 and NVIDIA A100 Specs Comparison
| Specification | NVIDIA A100 | NVIDIA H100 |
|---|---|---|
| Architecture | Ampere | Hopper |
| Transistors | 54.2 billion | 80 billion |
| GPU Memory | Up to 80 GB HBM2e | Up to 80 GB HBM3 |
| Memory Bandwidth | Up to 2 TB/s | Up to 3 TB/s |
| FP32 Performance | 19.5 TFLOPs | 67 TFLOP |
| FP64 Performance | 9.7 TFLOPs | 34 TFLOP |
| Tensor Performance | 312 TFLOPs | Up to 1,000 TFLOPs (est.) |
| Multi-Instance GPU (MIG) | Up to 7 MIGs | Up to 7 MIGs |
| Interconnect | NVIDIA NVLink/NVSwitch | NVIDIA NVLink/NVSwitch |
| Form Factor | SXM4, PCIe 4.0 | SXM5, PCIe 5.0 |
| TDP | 400 Watts | 700 Watts (est.) |
Advancing Data Center Performance with NVIDIA's Next-Generation GPUs
As the technological landscape continually advances, it's important to stay ahead with the most efficient and powerful tools available. The NVIDIA A100, a staple in high-performance computing, has reached its end-of-life (EOL) stage, making it crucial for users to consider upgrading to newer, more capable models. NVIDIA's H100, with its superior performance metrics, stands as the logical next step for those seeking to enhance their computational capabilities. Additionally, with the impending release of the H200, prospects for further advancements in processing power and efficiency are on the horizon. AMAX excels in integrating these cutting-edge technologies into data center solutions, ensuring your infrastructure remains at the forefront of innovation.