
GPU clusters have revolutionized high-performance computing (HPC), enabling organizations to tackle complex computational problems with incredible speed and efficiency. These clusters harness the immense power of graphics processing units (GPUs), which are specialized processors designed to handle massive parallel computing tasks. In this article, we will explore the capabilities of GPU clusters, their role in HPC, key features, emerging trends, and the challenges involved in their implementation.
Understanding GPU Clusters
GPU clusters are a collection of interconnected GPUs that work together to execute computationally intensive tasks in parallel. Each GPU consists of hundreds or thousands of smaller cores, allowing them to handle a multitude of tasks simultaneously. By leveraging the parallel processing capabilities of GPUs, clusters can process vast amounts of data at lightning-fast speeds, making them ideal for HPC applications.

What are GPU Clusters?
GPU clusters are a powerful tool in the world of computing. They are designed to tackle complex tasks that require significant computational power. These clusters are made up of multiple GPUs that work together to perform calculations and process data in parallel. This parallel processing capability allows for faster execution times and increased efficiency.
Imagine a scenario where you need to analyze massive amounts of data in a short amount of time. A single GPU might take hours or even days to complete the task. However, by utilizing a GPU cluster, you can distribute the workload across multiple GPUs, significantly reducing the processing time. This is achieved by dividing the data into smaller chunks and assigning each chunk to a different GPU within the cluster. Each GPU then processes its assigned data independently, and the results are combined to obtain the final output.
Furthermore, GPU clusters are particularly well-suited for tasks that involve complex mathematical calculations, such as simulations, machine learning, and data analytics. These tasks often require performing the same operation on a large dataset repeatedly. GPUs excel at this type of computation due to their ability to execute thousands of threads simultaneously. By harnessing the power of multiple GPUs in a cluster, the overall performance and speed of these calculations can be greatly enhanced.
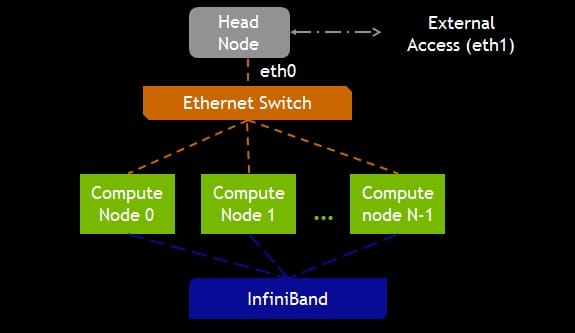
The Architecture of GPU Clusters
GPU clusters typically follow a distributed computing model, where multiple computing nodes are interconnected through high-speed network connections. Each node contains one or more GPUs, as well as CPU cores for handling tasks that are not GPU-accelerated. This architecture facilitates efficient data distribution and parallel execution, maximizing the overall performance of the cluster.
At the heart of a GPU cluster is the interconnection network, which enables communication between the nodes. This network plays a crucial role in ensuring that data can be transferred quickly and efficiently between GPUs, allowing for easy collaboration and coordination. High-speed network technologies, such as InfiniBand or Ethernet, are commonly used to achieve low-latency and high-bandwidth communication within the cluster.
In addition to the interconnection network, GPU clusters also require a management system to coordinate the activities of the individual nodes. This management system oversees tasks such as load balancing, job scheduling, and fault tolerance. It ensures that the workload is evenly distributed among the GPUs and that any failures or errors are handled gracefully, minimizing the impact on the overall performance of the cluster.
Moreover, the architecture of GPU clusters can vary depending on the specific requirements of the application or organization. Some clusters may consist of homogeneous GPUs, where all the GPUs within the cluster are of the same type and configuration. Others may be heterogeneous, incorporating different types of GPUs to leverage their unique strengths for specific tasks. The choice of architecture depends on factors such as the workload characteristics, budget constraints, and desired performance objectives.
GPU clusters are a powerful computing resource that enables the efficient execution of computationally intensive tasks. By harnessing the parallel processing capabilities of GPUs and leveraging a distributed computing model, these clusters can process vast amounts of data at incredible speeds. With their ability to accelerate complex calculations and handle demanding workloads, GPU clusters have become an indispensable tool for researchers, scientists, and organizations across various industries.

InfiniBand Networking, RDMA, and Their Role in Driving GPU Clusters
GPU clusters have been pivotal in advancing high-performance computing (HPC), but their effectiveness and efficiency owe much to innovations in network technologies, specifically InfiniBand and Remote Direct Memory Access (RDMA). These technologies have been instrumental in overcoming the data transfer and communication challenges inherent in GPU cluster operations, significantly enhancing their performance.
InfiniBand Networking in GPU Clusters
InfiniBand is a high-performance network architecture often used in HPC environments, particularly in GPU clusters. It provides several advantages over traditional Ethernet networking, especially in terms of bandwidth, latency, and scalability – all critical factors in the efficient operation of GPU clusters.
- High Bandwidth and Low Latency: InfiniBand networks offer high data transfer rates and low latency, which are essential for the rapid communication required between GPUs in a cluster. This rapid data exchange is crucial for parallel processing tasks, where time delays can significantly impact overall performance.
- Scalability: InfiniBand networks can efficiently scale to accommodate the growing size and complexity of GPU clusters. This scalability ensures that as more GPUs are added to meet increasing computational demands, the network can support the enhanced data flow without becoming a bottleneck.
- Reliability and Efficiency: InfiniBand also provides mechanisms for error handling and quality of service, ensuring reliable and efficient data transmission across the network, which is vital for maintaining the integrity of complex computations in HPC tasks.
Remote Direct Memory Access (RDMA) and GPU Clusters
RDMA plays a critical role in optimizing the performance of GPU clusters. It allows for the direct transfer of data between the memory of different machines, bypassing the CPU to reduce latency and CPU load. This capability is particularly beneficial in GPU clusters for several reasons:
- Efficient Data Transfer: RDMA enables more efficient data transfer between GPUs in a cluster, which is essential for tasks that require frequent and rapid data exchange. By reducing data transfer times, RDMA enhances the overall performance of GPU clusters.
- Reduced CPU Overhead: By allowing direct memory access, RDMA reduces the burden on the CPU, freeing it to perform other critical tasks. This efficiency is particularly important in GPU clusters where the CPU and GPUs need to work in tandem for optimal performance.
- Enhanced Parallel Processing: RDMA supports the parallel processing capabilities of GPU clusters by ensuring that data is quickly and efficiently shared between nodes. This capability is crucial for applications that require real-time data processing and analysis.
The Synergy of InfiniBand, RDMA, and GPU Clusters
The combination of InfiniBand networking and RDMA technology has been a game-changer for GPU clusters. This synergy has enabled faster and more efficient communication between GPUs, enhancing the capabilities of GPU clusters in processing vast amounts of data and executing complex parallel computing tasks.
The use of InfiniBand and RDMA in GPU clusters exemplifies how advancements in networking technologies can significantly impact the performance and capabilities of HPC systems. As these technologies continue to evolve, they will undoubtedly unlock even greater potential in GPU clusters, driving further innovations in high-performance computing applications.
The Role of GPU Clusters in High-Performance Computing
High-performance computing (HPC) has revolutionized the way organizations tackle complex problems and process vast amounts of data. In recent years, GPU clusters have emerged as a game-changer in the field of HPC, offering significant advantages over traditional CPU clusters.
GPU Clusters vs Traditional CPU Clusters
When it comes to HPC, the difference between GPU clusters and traditional CPU clusters is like night and day. CPUs, or central processing units, are designed to handle a few complex tasks sequentially. On the other hand, GPUs, or graphics processing units, excel at processing numerous simpler tasks in parallel. This parallelism allows GPU clusters to achieve immense computational power, enabling organizations to solve complex problems in a fraction of the time it would take with CPU clusters.
Imagine a scenario where a CPU cluster is tasked with analyzing a massive dataset. The CPUs would process the data one task at a time, sequentially moving from one task to the next. This sequential processing can be time-consuming and inefficient, especially when dealing with large datasets.
Now, picture a GPU cluster taking on the same task. The GPUs would divide the dataset into smaller chunks and process them simultaneously, in parallel. This parallel processing allows for a significant speedup in data analysis, as multiple tasks are executed concurrently. The computational power unleashed by GPU clusters is truly remarkable, revolutionizing the field of HPC.
The Impact of GPU Clusters on Data Processing Speed
One of the most remarkable aspects of GPU clusters is the speed at which they process data. The ability to perform matrix calculations, simulations, and simulations in real-time is a game-changer for organizations across various industries.
In scientific research, for example, GPU clusters enable researchers to analyze complex data sets and run simulations in real-time. This rapid data analysis allows for faster insights and decision-making, accelerating the pace of scientific discoveries. Whether it's simulating the behavior of molecules or studying the dynamics of the universe, GPU clusters have become an invaluable tool for scientists pushing the boundaries of knowledge.
In the financial industry, GPU clusters have revolutionized the field of financial modeling. Complex algorithms that were once time-consuming to run can now be executed in a fraction of the time. This increased processing speed enables financial institutions to make faster and more accurate predictions, helping them stay ahead in a highly competitive market.
Artificial intelligence (AI) is another field where GPU clusters have made a significant impact. AI algorithms often require massive amounts of data to be processed and analyzed. With GPU clusters, organizations can train AI models faster, allowing for more efficient machine learning and improved AI capabilities. This has opened up new possibilities in areas such as autonomous vehicles, natural language processing, and computer vision.
The impact of GPU clusters on data processing speed is fundamentally transforming the world. They have redefined the way organizations handle complex tasks, enabling faster insights, more accurate predictions, and incredible novel discoveries.

NVIDIA, CUDA, and the Evolution of GPU Technology - The H100 and H200 GPUs
In the realm of GPU clusters and high-performance computing, NVIDIA stands as a key player, particularly with its CUDA platform and the latest GPU innovations, the H100 and H200. These advancements by NVIDIA have significantly contributed to the evolution and enhancement of GPU capabilities, making them more adept for complex computational tasks.
NVIDIA and Its Impact on GPU Clusters
NVIDIA, a pioneer in graphics processing technology, has been instrumental in the evolution of GPU clusters. Their GPUs are not just central to rendering graphics but have become vital for a wide range of computational tasks in various fields, including scientific research, artificial intelligence, and data analytics.
CUDA: Unleashing the Power of NVIDIA GPUs
CUDA (Compute Unified Device Architecture) is a parallel computing platform and application programming interface (API) model created by NVIDIA. It allows software developers to use a CUDA-enabled GPU for general purpose processing (an approach known as GPGPU, General-Purpose computing on Graphics Processing Units).
- Parallel Processing Capabilities: CUDA gives programmers access to the virtual instruction set and memory of the parallel computational elements in NVIDIA GPUs. This access revolutionizes how computations are handled, enabling more efficient parallel processing and significantly boosting the performance of GPU clusters.
- Versatility and Accessibility: CUDA supports various programming languages, including C, C++, and Fortran, making it accessible to a wide range of developers. This versatility has allowed for the broad adoption of CUDA in various computational and scientific applications.

The NVIDIA H100 and H200 GPUs
NVIDIA’s introduction of the H100 and H200 GPUs marks a significant leap in GPU technology, offering even more power and efficiency for HPC and AI applications.
- H100 GPU: The H100, part of NVIDIA's Hopper architecture, is designed specifically for AI and HPC workloads. It is built to handle the immense computational demands of large-scale AI models and high-performance computing tasks. The H100's architecture allows for faster data processing and enhanced parallel computing capabilities, making it an ideal choice for demanding AI and HPC applications.
- H200 GPU: Following the H100, the H200 represents further advancement in GPU technology, providing even greater computational power and efficiency. While detailed specifications and capabilities of the H200 are yet to be fully unveiled, it is expected to push the boundaries of GPU performance, offering unprecedented processing speeds and capabilities for next-generation AI and HPC applications.
The Role of H100 and H200 in Advancing GPU Clusters
The introduction of the H100 and the anticipated H200 GPU is set to further revolutionize the capabilities of GPU clusters. With these advanced GPUs, NVIDIA continues to drive the envelope in processing speed, efficiency, and the ability to handle increasingly complex computational tasks. The H100 and H200 GPUs are expected to:
- Enhance AI and Machine Learning: By providing more powerful processing capabilities, these GPUs will enable more complex and larger-scale AI and machine learning models, facilitating advancements in fields such as natural language processing, autonomous vehicles, and predictive analytics.
- Boost HPC Applications: For high-performance computing, the H100 and H200 GPUs will enable faster simulations, data analysis, and scientific research, aiding in breakthrough discoveries and innovations across various scientific fields.
- Improve Energy Efficiency: With advancements in GPU technology, these new models are also expected to be more energy-efficient, a critical factor in large-scale computing environments.
Key Features of GPU Clusters
GPU clusters offer a multitude of key features that make them a powerful tool for high-performance computing. Let's dive deeper into some of these features:
Parallel Processing Capabilities
The parallel processing capabilities of GPU clusters are their defining feature. Each GPU in the cluster can execute multiple threads simultaneously, dividing a task into smaller sub-tasks that can be processed in parallel. This parallelism greatly accelerates the overall computing speed, making GPU clusters highly efficient for demanding computational workloads.
Imagine a scenario where a research team is working on a complex simulation that requires extensive calculations. With a GPU cluster, the workload can be divided into smaller chunks, and each GPU can handle a portion of the calculations simultaneously. This parallel processing capability significantly reduces the time required to complete the simulation, enabling researchers to obtain results faster and iterate on their work more efficiently.
Furthermore, the parallel processing capabilities of GPU clusters are not limited to scientific simulations. Industries such as finance, healthcare, and entertainment can also benefit from the immense computing power provided by GPU clusters. For example, financial institutions can use GPU clusters to accelerate complex risk analysis calculations, while healthcare organizations can leverage them for medical imaging processing and analysis.
Scalability and Flexibility
GPU clusters are highly scalable, allowing organizations to easily expand their computational resources by adding more GPUs or computing nodes. This scalability is crucial for accommodating the ever-increasing demands of modern computational workloads.
Let's consider a scenario where a company experiences a sudden surge in computational requirements due to a new project or increased customer demand. With a GPU cluster, the organization can effectively scale up its computing power by adding more GPUs or computing nodes to the cluster. This flexibility ensures that the company can meet the growing demands without significant disruptions or delays.
Moreover, GPU clusters support a wide range of programming languages and frameworks, providing developers with the flexibility to leverage their existing codebase and tools. This compatibility allows organizations to easily integrate GPU clusters into their existing workflows and infrastructure without the need for a complete overhaul.
For instance, a software development company that has been using Python for their data analysis tasks can continue using the same programming language with GPU clusters. They can utilize libraries like TensorFlow or PyTorch to harness the power of GPUs for accelerating their machine learning models. This flexibility saves time and resources that would otherwise be spent on retraining the development team or rewriting existing code.
GPU clusters offer parallel processing capabilities and scalability, making them highly efficient for demanding computational workloads. Their flexibility in supporting various programming languages and frameworks allows organizations to integrate them into existing workflows. Whether it's scientific simulations, financial analysis, or medical imaging, GPU clusters are a valuable asset for industries across the board.

The Future of High-Performance Computing with GPU Clusters
Emerging Trends in GPU Clusters
The field of GPU clusters is constantly evolving, with researchers and developers exploring innovative ways to enhance their capabilities. One emerging trend is the integration of machine learning algorithms directly into GPU clusters, enabling real-time data analysis and decision-making. Another trend is the use of hybrid CPU-GPU clusters, which combine the strengths of both processors for even greater performance.
Challenges and Solutions in GPU Cluster Implementation
While GPU clusters offer immense processing power, their implementation can present challenges. Ensuring effective workload distribution among the GPUs, managing data transfer between nodes, and synchronizing computations across multiple GPUs are some of the key challenges. However, advancements in cluster management software and efficient algorithms are addressing these challenges, making GPU clusters more accessible and easier to deploy.
Harnessing the Power of GPU Clusters for High-Performance Computing
GPU clusters have revolutionized high-performance computing, offering unprecedented speed and efficiency. Their parallel processing capabilities, scalability, and flexibility make them an invaluable tool for organizations seeking to tackle complex computational problems. As emerging trends continue to shape the field of GPU clusters and challenges are overcome, their potential for advancing various domains, from scientific research to artificial intelligence, will only continue to grow.