
Choosing the Right Turnkey Data Center Solution
The ever-increasing complexity and size of AI models demand more advanced solutions for handling elaborate AI use cases. Many organizations require the capability to run numerous AI workloads simultaneously. However, there is a specific user group with single-workload memory needs that surpass the capabilities of standard GPUs and even extensive multi-GPU clusters.
NVIDIA’s newest NVIDIA DGX™ GH200 made significant upgrades to the previous NVIDIA DGX SuperPOD™ model to provide a solution capable of enhancing the memory and processing capabilities of GPUs and CPUs while scaling efficiently without performance degradation, all while maintaining the simplicity of a single-GPU programming model.
Organizations such as cloud service providers, hyperscalers, major research entities, and others at the forefront of AI innovation require extremely specialized computing. NVIDIA DGX solutions are engineered for developing giant model AI with hundreds of petaFLOPS of FP8 performance.
For those building large-scale AI infrastructure, it's crucial to understand the key differences between the NVIDIA DGX GH200 and the NVIDIA DGX H100 Tensor Core GPU systems. While both models are highly capable, the DGX GH200 is specifically designed for applications that require extensive memory and processing power for single, large-scale workloads. Whereas the NVIDIA H100, while versatile, may not offer the same level of specialized performance for such extensive tasks. Below is a detailed guide on choosing which NVIDIA DGX system is right for your next enterprise AI deployment.

NVIDIA DGX H100 SuperPOD Overview
The NVIDIA DGX SuperPOD offers an all-encompassing, turnkey experience, blending sophisticated white-glove services that streamline deployment, simplify operations, and adeptly manage complexities for AI enterprises. The NVIDIA SuperPOD offers advanced power efficiency, a standout feature for a supercomputer of its class. The NVIDIA DGX SuperPOD signifies a leap forward in AI, setting new standards for the scale and intricacy of models.
Key Features of the NVIDIA DGX SuperPOD include:
- A harmonized combination of NVIDIA DGX™ H100 or NVIDIA DGX A100 systems, NVIDIA Networking, and high-performance storage.
- An integrated software ecosystem featuring NVIDIA AI Enterprise and NVIDIA Base Command™ Platform.
- NVIDIA Base Command powers the infrastructure, providing enterprise-grade orchestration, cluster management, and optimized AI workload handling.
- Extensive Lifecycle Services, covering everything from capacity planning, data center design, performance projection, to post-install testing and management.
- AMAX white-glove implementation service, ensuring seamless deployment and operation.

NVIDIA DGX GH200 Overview
The NVIDIA DGX GH200 builds upon the previous NVIDIA DGX SuperPOD to integrate the new NVIDIA Grace™ Hopper Superchip, engineered to accommodate workloads beyond the memory limits of a single system. With a shared memory space of 19.5TB across 32 NVIDIA Grace Hopper Superchips, it grants developers access to more than 30 times the fast-access memory typically available, enabling the construction of vast models[1]. The NVIDIA DGX GH200 is the first of its kind to integrate NVIDIA Grace Hopper Superchips with the NVIDIA® NVLink® Switch System, allowing 32 GPUs to operate cohesively as a singular, data-center-scale GPU. For expanded computing prowess, multiple DGX GH200 systems can interconnect via NVIDIA InfiniBand. This design boasts a bandwidth 10 times greater than its predecessors, merging the capabilities of a colossal AI supercomputer with the ease of programming a single GPU.
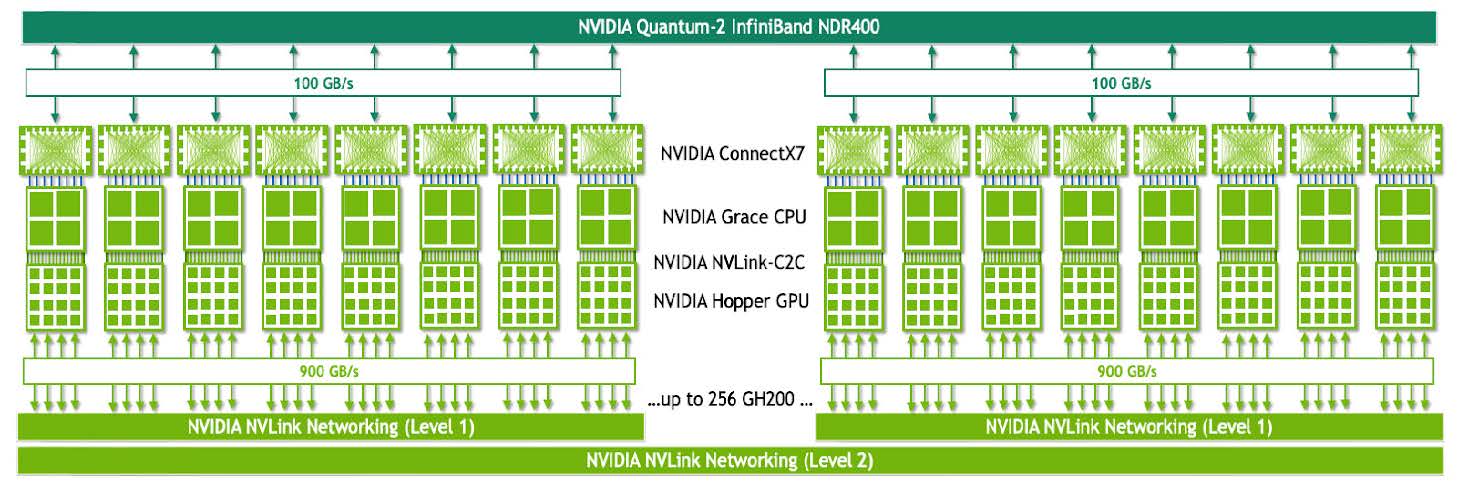
Key Features of NVIDIA DGX GH200 include:
- Integration of 32 NVIDIA Grace Hopper Superchips with NVIDIA NVLink.
- A substantial, unified GPU memory space of 19.5TB.
- GPU-to-GPU bandwidth of 900 gigabytes per second (GB/s).
- A formidable 128 petaFLOPS of FP8 AI performance.
- Access to NVIDIA Base Command™ and NVIDIA AI Enterprise software.
- A comprehensive, white-glove implementation service by AMAX.

Key Differences Between NVIDIA DGX GH200 and NVIDIA DGX H100 SuperPOD
- Design Focus and Intended Use:
- NVIDIA DGX GH200: This is specifically designed for dealing with extremely large and complex AI models. It is tailored for scenarios where there is a need for vast memory and processing power for single, large-scale AI workloads. It's ideal for organizations pushing the boundaries of AI with massive model sizes and complexities.
- NVIDIA DGX SuperPOD: The NVIDIA SuperPOD, equipped with NVIDIA H100 GPU, is a more comprehensive solution aimed at broader high-performance computing (HPC) and AI tasks. It's designed for enterprises requiring scalable and agile performance across a range of challenging AI and HPC workloads. This makes it suitable for a wide array of AI applications, including those that need multi-node training and large compute clusters.
- Computational Power and Hardware Configuration:
- NVIDIA DGX GH200: Similar to the NVIDIA DGX H100 SuperPOD, the DGX GH200 system boasts an AI training performance of 1 exaflops at FP8 precision, augmented by sparsity support. Additionally, it offers 7.4 times more memory, making it well-equipped to handle substantial training and recommender workloads[2]. This model is the first to integrate NVIDIA Grace Hopper Superchips with the NVIDIA NVLink Switch System, allowing 32 GPUs to function as one data-center-size GPU.
- NVIDIA DGX SuperPOD: This system combines multiple NVIDIA DGX H100 units (each featuring powerful NVIDIA GPUs), along with NVIDIA Networking and high-performance storage. The NVIDIA SuperPOD with NVIDIA H100 is designed to provide balanced and scalable performance for a variety of compute-intensive tasks, not just those requiring immense single-model memory.
- Scalability and Infrastructure Management:
- NVIDIA DGX GH200: Offers immense scalability and is particularly focused on expanding memory and processing capabilities for single, large-scale AI workloads.
- NVIDIA DGX SuperPOD: Provides a comprehensive AI infrastructure solution, including orchestration, cluster management, and a suite of optimized software for AI workloads, making it more versatile for a range of applications.
NVIDIA DGX GH200 vs NVIDIA DGX SuperPOD Specs
| Specification | NVIDIA DGX GH200 | NVIDIA DGX SuperPOD |
|---|---|---|
| Memory | 19.5TB shared memory across 32 Grace Hopper Superchips | 640 GB of aggregated HBM3 memory with 24 TB/s of aggregate memory bandwidth |
| Processing Units | 32 Grace Hopper Superchips | Dual Intel® Xeon® Platinum 8480C processors, 112 Cores total, 2.00 GHz (Base), 3.80 GHz (Max Boost) with PCIe 5.0 support, with 2 TB of DDR5 memory. |
| GPU Architecture | Integration with NVIDIA NVLink Switch System, allowing 32 GPUs to act as one | 40+ NVIDIA DGX H100 system with eight 80 GB H100 GPUs |
| Bandwidth | GPU-to-GPU bandwidth of 900 gigabytes per second (GB/s) | Single-node bandwidth of at least 40 GBps to each DGX H100 system per GPU @ 900 GBps with fourth generation of NVIDIA NVLink |
| AI Performance | 128 petaFLOPS of FP8 AI performance | 32 petaFLOPS at FP8 precision |
| Software | NVIDIA Base Command™ and NVIDIA AI Enterprise software | NVIDIA AI Enterprise, NVIDIA Base Command™ Platform, and other software services depending on the configuration |
| Scalability | Designed for single, large-scale AI workloads with extensive scalability in memory and processing power | Built for a range of AI and HPC workloads with scalable performance across multiple nodes and tasks |
| Implementation Services | Comprehensive, white-glove implementation service | Full lifecycle professional services including planning, deployment, training, and optimization |
| Primary Use Cases | Tailored for extremely large and complex AI models, particularly those requiring vast memory and processing power for single workloads | Versatile for a broad range of AI and HPC tasks, including multi-node training and large compute clusters |
Sources for DGX Specifications [3] [4].

Engineering your Next On-Prem Large Scale AI Deployment
Choosing between the NVIDIA DGX GH200 and the NVIDIA DGX SuperPOD hinges on your specific AI and high-performance computing needs. If your organization is focused on developing extremely large and complex AI models, requiring substantial memory and processing power for single workloads, the NVIDIA DGX GH200 is your ideal choice. It offers unparalleled memory capacity and a unified GPU architecture tailored for such tasks. On the other hand, if you need a versatile and scalable solution for a broad range of AI and HPC applications, including multi-node training and large compute clusters, the NVIDIA DGX SuperPOD may be more suitable.
For those looking to make an informed decision on the right AI infrastructure, AMAX offers expert consultation and tailored solutions. Our team at AMAX specializes in designing and delivering cutting-edge IT infrastructure, perfectly suited to your organizational needs. Whether it's choosing the right NVIDIA DGX system or customizing an entire AI infrastructure, we're here to guide you every step of the way.